January 26, 2023 | Blog, Data Analysis, Neo4j
Fahran Wallace and Ebru Cucen’s most recent blog post is part 1 of a three-part series. They investigate how OpenCredo ingested 400 million nodes with a billion relationships into Neo4j.

So you’ve got a few terabytes of data you’d love to explore in a graph. But you’ve run a well-tuned apoc.load.json on a small sample of data, done some back-of-the-envelope maths, and found periodic load will not be as helpful or as quick as you thought. It will take a week to ingest your full dataset. What’s next?
After a couple of ingestion projects we have done for our clients, we found that the first production-size (terabyte-sized) graph database ingestion process can be trickier than it first appears. Source data varies in shape and size, the time it takes for traditional approaches can take up to hours – if not days – to parse and load into Neo4j. Here we want to share the lessons learned to cover tips and tricks to run your ingestion process smoothly.
It is a METL process, a standard ETL process, with a twist we added, as it starts with modelling. This is a critical, but usually forgotten step, it helps us to think about the big picture and focus on what we need.
This blog post is divided into three smaller posts, the first post will cover the model and extraction phases of our approach and the second and third posts will cover transformation and loading respectively.
*ETL is a more traditional choice of process and terminology that was more popular in the pre-cloud data warehouse era. In our case, we are loading data into BigQuery from the staging area and then importing it into a Neo4j database without any transformation (nor any filtering in our scenario since we knew we wouldn’t be using all the noisy source data we have) and this would require a more expensive licence.
Note: Neo4j has recently announced the loading process with GCP Dataflow, which can work when your EL phases are complete and you have a schema (whether you have structured or unstructured data). However, this blogpost covers the edge cases when custom preprocessing is required to unlock the capability to implement their suggested solution. I’m excited to try out this method, as I’m already a big fan of Apache Beam, the now open-sourced framework which backs Dataflow.
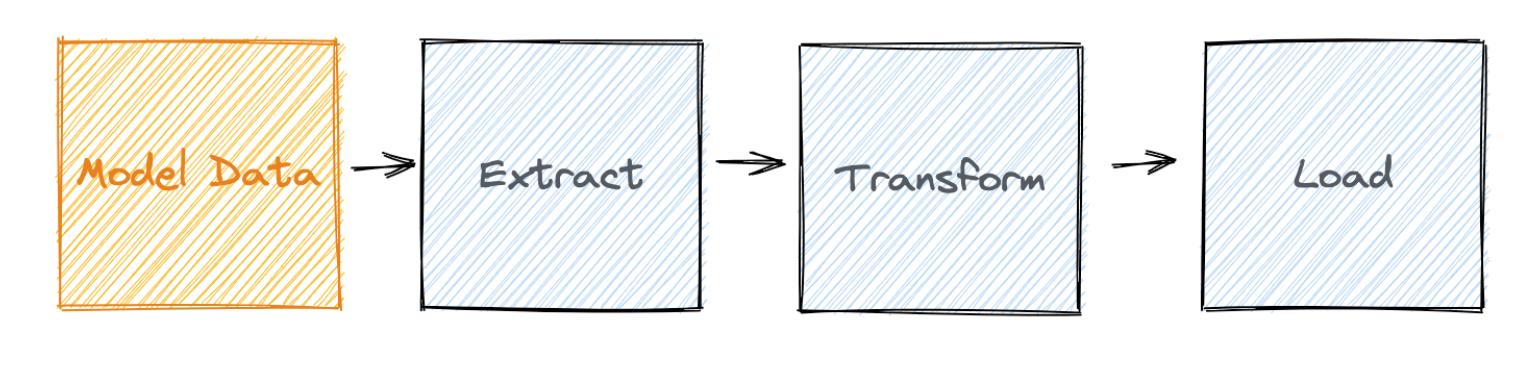
This is the rough technique we normally use when modelling graph data:
EXPLAIN and PROFILE commands are great for this). If necessary, iterate on your data model if the plan looks expensive.This process is much like deciding the degree of normalisation you require in a relational database. There is also no one “correct” model. It’s whether the model you’ve chosen is suitable for your use-case (i.e. the way of working and querying the data once it’s loaded) that is relevant.
I’ll illustrate this with an example covering a basic online shop.
A simple graph representation of a customer acquiring a product might look like this:
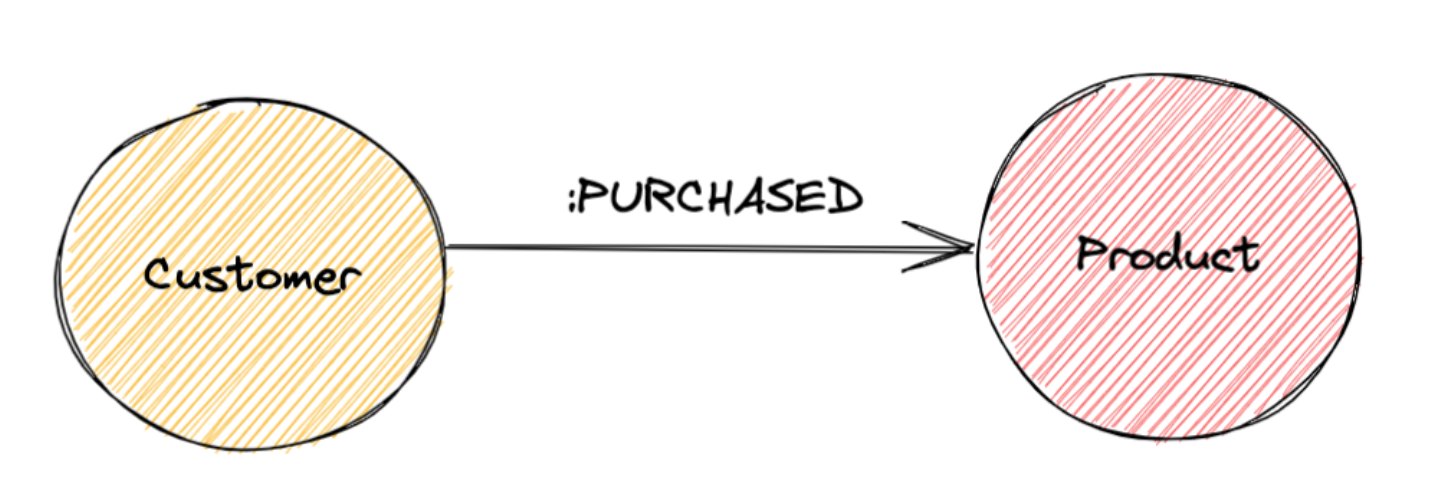
Now supposing we are handling multiple vendors, and we care where the customer got the product from.
![Graph diagram of the relationships between Customer, Product and Merchant.
(c:Customer)-[:PURCHASED]->(p:Product)<-[:SOLD]-(m:Merchant)<-[:IS_CUSTOMER_OF]-(c:Customer)](https://opencredo.com/wp-content/uploads/2023/01/image6-1024x714.png)
We must be sure to add relationship properties too, so we can still work out which merchant the customer bought a particular product from:
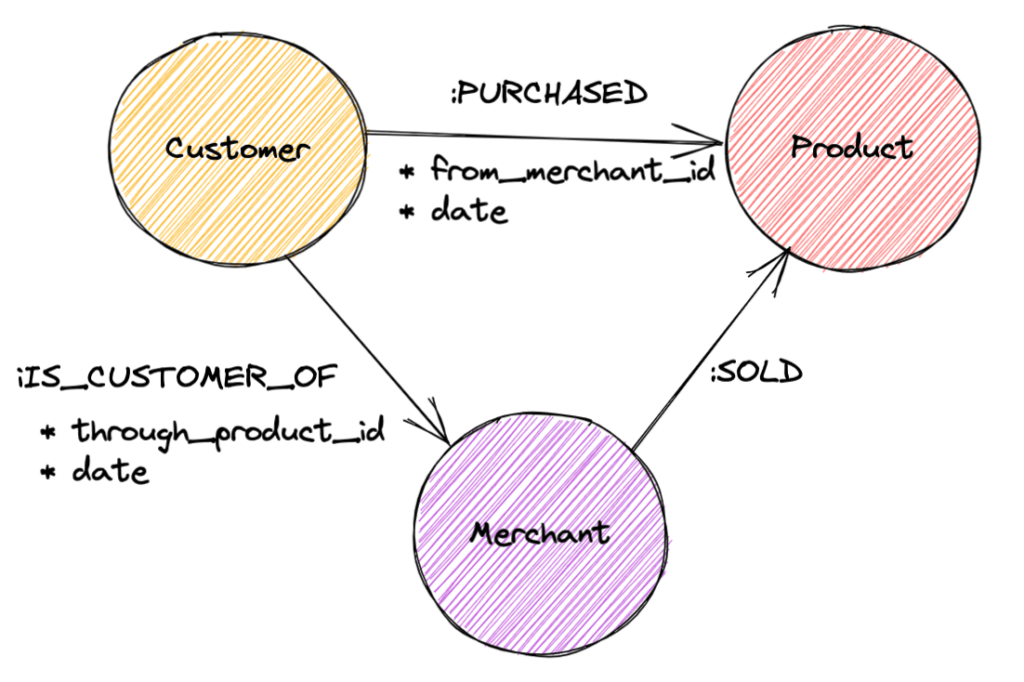
However, this might not be particularly efficient to query in some circumstances. For example, if we’re looking at the prices of products bought together from a particular merchant, we’ll have to start doing fiddly aggregations of fields on the :IS_CUSTOMER_OF and :PURCHASED relationships, which may not be particularly easy or efficient.
One way of solving this inflexibility is to add an intermediate node that more flexibly covers the relationship between this triangle of node types:
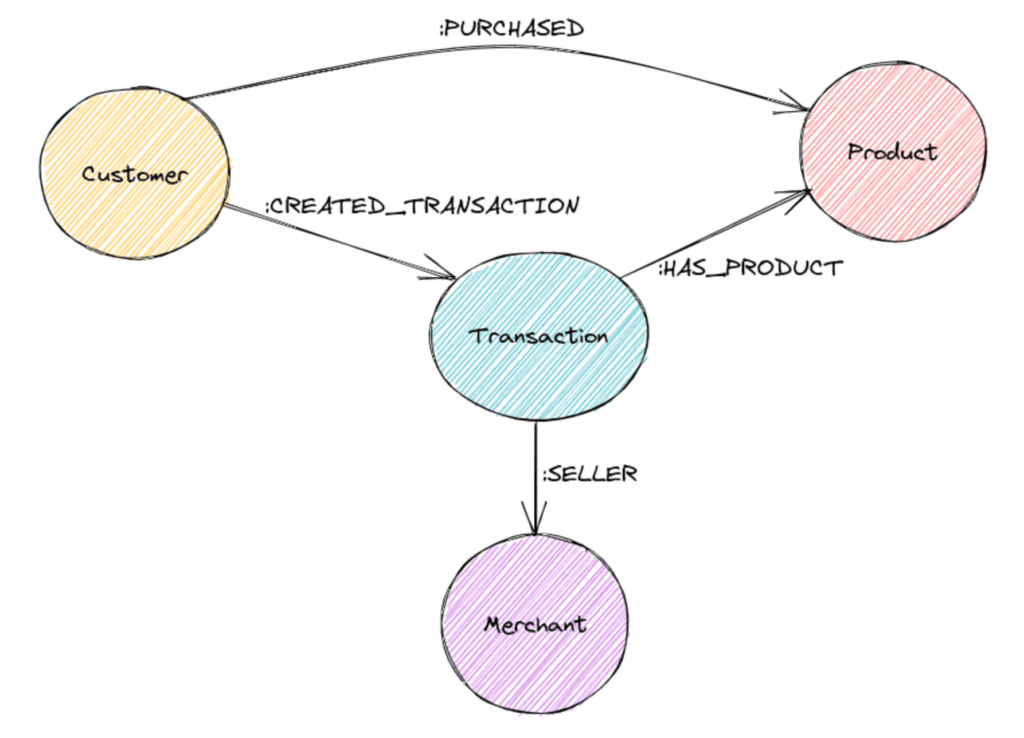
This modelling unlocks the power to run a query to explore the customer – merchant relationship as:
MATCH (c:Customer)-[:CREATED_TRANSACTION]->(t:Transaction)-[:IS_SELLER_OF]-(m:Merchant)
CALL {
WITH t OPTIONAL MATCH (t)-[:HAS_PRODUCT]-(p:Product)
WHERE p.name="Sapiens: A Brief History of Humankind" RETURN p
}
RETURN c, pNow the event of a merchant selling a product to a customer is encapsulated in a node, and we’ll be able to write the query above as a much simpler node traversal query. In general, if you’re fighting the inflexibility of a triangle of nodes when writing a query, adding an intermediate node is often a good call.
Adding one additional hop shouldn’t cause too many performance issues. However, if we’re very frequently traversing between our customers and their purchased products, we might want to introduce a virtual relationship to query the graph more efficiently.
Neo4j has more documentation of this process on their Graph Academy. Polishing up on that may well save time when you’re doing a big ingest!
The data engineer and software engineer within me disagree about this! The data engineer wants to keep everything, just in case it’s handy. The software engineer says “You Ain’t Gonna Need It”, so don’t import it.
As with everything – it depends – and the right answer is usually somewhere between the two extremes. In our recent case, the data was pretty flat, and barring a few fields of frustrating verbosity, most of the data was relevant to us, so we elected to keep at least a flat copy of everything. Be sensible, and trim anything that’s space-filling junk for you. Worst case, if it turns out it was important, you can just run ingestion again with that field.
Note, and a mild spoiler for parts 2 and 3: We’ll be using the neo4j-admin import tool to ingest the data, which is very fast because it writes the initial database files directly, instead of using transactions. This means that it will be much slower to add missing fields later on (because updates will require transactions). If re-running the ingestion again later is impractical, and if you’re not space-constrained, I would err on the side of keeping more data.
I’m a big fan of data formats that come with their own programmatically-defined schema. It typically means the author has been extremely specific about what data is valid, what all the possible shapes are, and so has saved me a bunch of work over the years.
Our dataset was actually very well documented, but as it was JSON (and JSON schema isn’t ubiquitous yet), there was no code-defined schema available.
The neo4j-admin import tool we will use exclusively works with the CSV format for ingestion, so we had to convert our JSON to CSV. CSV is also one of my least-favourite data formats, as it’s both very fussy about field order, but is not smart enough to know when you’ve accidentally switched around your columns. This means you can silently end up with mislabeled data if you’re not careful.
In the face of this, we elected to be specific about which fields were picked out, and the ordering of those fields in our output. In short, we programmatically defined a schema ourselves. If we had allowed the JSON itself to dictate the structure of the CSV, there was a risk that different runs of the ingestion process would result in fields being added in different orders, producing incompatible CSV files.
A drawback of Neo4j is that properties can’t be nested. A property can’t be a map, you can’t have lists of lists etc. Here you’re going to have to make a choice between
As a simple example, the JSON for one of our models had a section called “ids”, which contained a selection of industry-standardised identifiers:
"ids": {
"foo": "xxxxxxxx",
"bar": "yyyyyyyy"
}
This can simply be flattened into the following structure, and there are plenty of libraries that’ll help you get there:
"ids.foo": "xxxxxxxx",
"ids.bar": "yyyyyyyy"
The flattening is substantially uglier in this case. For the data we were pretty certain we weren’t going to use but would have caused a great increase in the number of nodes, we elected to just embed the property as a JSON string. Queryable if necessary, but not getting in the way. For the data it was clear we’d need, we did extract each entry in the list into a node.
Now we have the data modelled and extracted, the next blog post in the series will look at how to transform the data ready for the last stage in the process – loading.
SHARE





Platform Engineering Day Europe 2024 – Maturing Your Platform Engineering Initiative (Recording)
Watch the recording of our CEO/CTO, Nicki Watt from the KubeCon + CloudNativeCon 2024 on her talk “To K8S and Beyond – Maturing Your Platform…
GOTO Copenhagen 2023 – The 12 Factor App For Data (Recording)
Watch the recording of our Technical Delivery Director, James Bowkett from the GOTO Copenhagen 2023 conference for his talk ‘The 12 Factor App For Data’
The 2023 Mayor’s Business Climate Challenge (BCC) – Final Part
Learn more about our efforts and our progress towards becoming an environmentally friendly company for the Mayor’s Business Climate Challenge (BCC) in 2023 in this…