August 8, 2017 | Cassandra
Recently, the sad news has emerged that Basho, which developed the Riak distributed database, has gone into receivership. This would appear to present a problem for those who have adopted the commercial version of the Riak database (Riak KV) supported by Basho.
This blog is written exclusively by the OpenCredo team. We do not accept external contributions.

Like all businesses, there are no guarantees that a commercial entity set up around an Open Source project will become viable long-term. In our opinion, a thriving and engaged Open Source community represents a better indicator of safe adoption than any particular vendor. A solid community is more likely to survive an individual actor or entity leaving the project.
So, is this the case for Riak? Let’s take an outsider’s view of the health of the Riak open source community. We’ll compare it against two other leading NoSQL databases (MongoDB, Cassandra) and one other high performing open source project (Terraform).
N.B. when we refer to Riak we mean Riak KV. Basho also developed a Riak TS product for timeseries data which contains more radical changes built on top of Riak KV.
Riak
https://github.com/basho/riak/graphs/contributors

MongoDB
https://github.com/mongodb/mongo/graphs/contributors

Cassandra
https://github.com/apache/cassandra/graphs/contributors

Terraform
https://github.com/hashicorp/terraform/graphs/contributors

Please note the scale differences in the graphs. However, simply from observing the trends in this data, we can see that the health of contributions to the Riak open source project is less strong than the comparison projects.
Watchers
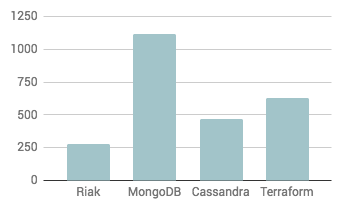
Stars
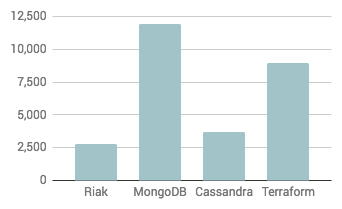
Forks
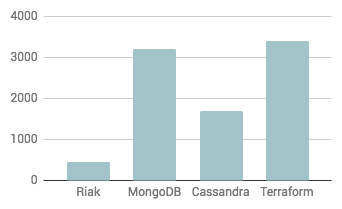
Again, levels of engagement with the project appear lower than the comparison projects.
Based on the data above, the closure of Basho would appear to leave users of Riak KV in a difficult position. Community engagement with the project appears to have tailed off and Riak users now have no off-the-shelf support option.
Perhaps this issue is compounded by the fact that Riak is written in Erlang – a language which, whilst universally respected for building distributed systems, is realistically still niche; for example, it does not enter the top 20 in the latest RedMonk Language Ratings, and sits at 36 on the IEEE Spectrum: Top Programming Languages 2017.
We hope that the community will rally round to support the long term survival of Riak. To this point, we note experts in Erlang, such as Erlang Solutions with existing expertise and investment in Riak.
Whether this will happen or not is unclear. Assuming the worst – that the long term use of Riak become unsustainable – let’s back up and look at Riak KV in context and assess whether there are any good alternatives.
Riak was originally based on the paper published in 2007 about the Dynamo highly available key-value store used to power core Amazon services. To summarise:
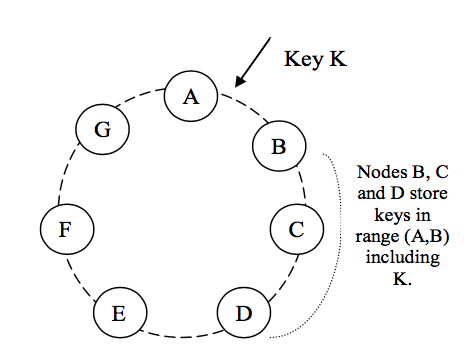
On the whole, Riak KV is faithful to the Dynamo paper. Yes, it is written in Erlang and not Java. It adds buckets to provide namespacing and “full bucket” reads across multiple keys. It adds full text search, map reduce queries, new storage backends and distributed data types (CRDTs). However, at its core, Riak is a key-value store with a read path, write path, consistency model and storage that aligns with Dynamo.
For more information see: Basho’s breakdown of the Dynamo paper and the Riak KV documentation.
OK, so when looking for alternatives to Riak KV let’s start by looking at other databases based on Dynamo. This includes several NoSQL alternatives, including Aerospike, Voldemort and Cassandra. Of these, the only database with solid commercial traction is Cassandra.
Open source Cassandra has traditionally been supported by Datastax, who provide Datastax Enterprise – a commercial offering with additional features. Again, however, we see change afoot as Datastax announced that it will no longer support open source distributions of Cassandra. As we have seen earlier however, the Cassandra open source community is reasonably healthy. So let’s take a look at the Cassandra model now
Cassandra merges the model of Dynamo with BigTable to create it’s own hybrid approach. This shares many features of Dynamo (consistent hashing, tunable consistency, read repair etc) but, diverges in other ways. The key difference is a move to a column family storage model which enables fast writes and range queries but requires a completely different approach to data modelling and querying. With this, the user experience of Cassandra is changed dramatically and makes a migration to Cassandra troublesome – despite the shared underlying technology components
As we have seen, while both Riak and Cassandra share a common inheritance via the Dynamo paper, this does not mean that Cassandra is a shoe-in replacement for Riak. What are the alternatives?
The leading non-relational open source persistence stores are MongoDB, Cassandra, HBase, Neo4j, Couchbase and CouchDB.
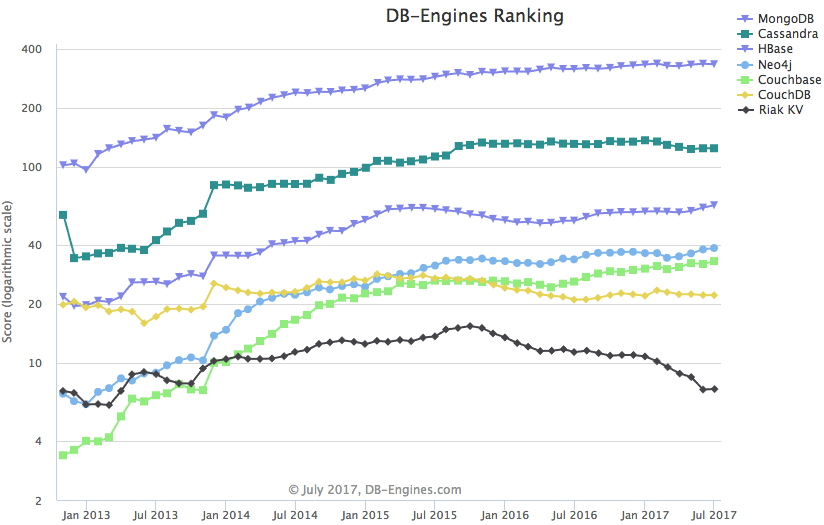 https://db-engines.com/en/ranking_trend
https://db-engines.com/en/ranking_trend
This represents the full spectrum of key-value, document, graph and column family databases. Perhaps the closest in data modelling terms is Couchbase which, like Riak, provides key-value, MapReduce and full text search. However, the underlying semantics of Couchbase are different and it generally prioritises consistency over availablility (as opposed to availability over consistency for Riak). This can lead to very different performance characteristics in production.
The reality is that the NoSQL and distributed data arena is complicated. To make informed decisions requires a solid understanding of the underlying semantics of each database – how it’s data model and querying characteristics will suit your data and use cases. As we have seen from Riak and Cassandra, even with a common root the fundamentals of each datastore can significantly diverge.
Choosing an alternative is further complicated by the requirement to assess the health and long term viability of the open source project. To be clear, there are many very healthy open source projects. Many of these are curated by open source organisations such as Apache and Cloud Native Computing Foundation. Open Credo is solidly committed to open source and has been since inception. However, there is an emerging challenge to open source which is growing rapidly and in alignment with other fundamental changes happening in infrastructure.
As an alternative to seeking support from an Open Source guardian or support organisation such as Basho, there are a number of managed service offerings available on the cloud. The businesses behind major public clouds: Google, Amazon and Microsoft are clearly well established – what may be less well known is their commitment to making their cloud offerings central to their businesses. From this, we may infer that the cloud vendors represent a stable, supported environment in which adoption of a database-as-a-service is a safe option.
There is insufficient space here to discuss these in depth so we will quickly review a couple of options:
For us there are two key take-aways.
When adopting an open source project, we recommend performing appropriate due diligence on both it’s “guardian” commercial entity and the community that supports it. It is community momentum which will sustain a project beyond disruptive events. Ideally the project will fall under the auspices of a leading Open Source organisation such as the Apache Software Foundation or Cloud Native Computing Foundation which can provide guidance and direction for the project.
Increasingly the public cloud vendors are targeting projects – both open source and commercial – with services that are both managed and integrated into their platform ecology. With the stability and convenience these provide, the balance may tip away from fear of lock-in towards broader cloud adoption. There are many database-as-a-service products on offer and these vary from multi-model to more specific document, NuSQL, key-value and columnar offerings.
If you are seeking help with Riak, NoSQL or designing your data architecture, get in touch!
SHARE







