February 25, 2013 | Neo4j
As part of our work, we often help our customers choose the right datastore for a project. There are usually a number of considerations involved in that process, such as performance, scalability, the expected size of the data set, and the suitability of the data model to the problem at hand.
This blog post is about my experience with graph database technologies, specifically Neo4j. I would like to share some thoughts on when Neo4j is a good fit but also what challenges Neo4j faces now and in the near future.

I would like to focus on the data model in this blog post, which for me is the crux of the matter. Why? Simply because if you don’t choose the appropriate data model, there are things you won’t be able to do efficiently and other things you won’t be able to do at all. Ultimately, all the considerations I mentioned earlier influence each other and it boils down to finding the most acceptable trade-off rather than picking a database technology for one specific feature one might fancy.
So when is a graph model suitable? In a nutshell when the domain consists of semi-structured, highly connected data. That being said, it is important to understand that semi-structured doesn’t imply an absence of structure; there needs to be some order in your data to make any domain model purposeful. What it actually means is that the database doesn’t enforce a schema explicitly at any given point in time. This makes it possible for entities of different types to cohabit – usually in different dimensions – in the same graph without the need to make them all fit into a single rigid structure. It also means that the domain can evolve and be enriched over time when new requirements are discovered, mostly with no fear of breaking the existing structure.
Effectively, you can start taking a more fluid view of your domain as a number of superimposed layers or dimensions, each one representing a slice of the domain, and each layer can potentially be connected to nodes in other layers.
More importantly, the graph becomes the single place where the full domain representation can be consolidated in a meaningful and coherent way. This is something I have experienced on several projects, because modeling for the graph gives developers the opportunity to think about the domain in a natural and holistic way. The alternative is often a data-centric approach, that usually results from integrating different data flows together into a rigidly structured form which is convenient for databases but not for the domain itself.
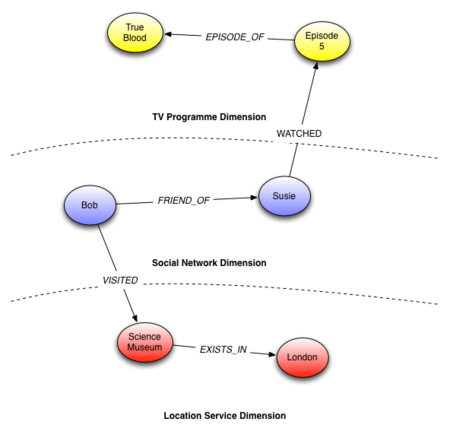
As an example to illustrate these points, let’s take a very simple Social Network model. Initially the graph simply consists of nodes representing users of the service together with relationships that link users who know each other. Those nodes and relationships represent one self-contained concept and therefore live in one “dimension” of the domain. Later, if the service evolves to allow users to express their preferences on TV shows, another dimension with the appropriate nodes and relationships can be added into the graph to capture this new concept. Now, whenever a user expresses a preference for a particular TV show, a relationship from the Social Network dimension through to the TV Shows dimension can be created.
In a similar fashion, if a location service is needed, the graph can be further enriched with a new dimension, independent from both the TV shows and Social Network dimensions. As the relationships between these different dimensions become richer over time new possibilities arise. For example, in the example illustrated in the diagram below, we can discover that since Susie is potentially interested in vampires, Bob might be willing to recommend a vampire gallery in the science museum that he visited last week.
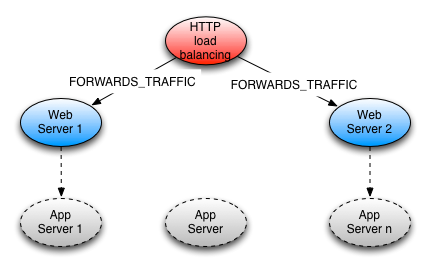
One particularly nice property of the graph model is that nodes don’t just have to represent concrete entities from the domain; more abstract – and therefore more powerful – concepts can be happily accommodated in the same graph too. For example, if you are modeling a computer network, components that cooperate to accomplish one logical task, such as load balancing some incoming traffic, can be all related through one node that represents that concept, hence enriching the graph and the range of possible queries.
When modelling a domain as a graph, it is important to think about the queries the model should answer. A distinguishing feature of a graph model is that good queries are sympathetic to the graph’s structure and vice-versa; they are a direct reflection of how entities relate to each other and therefore they can evolve in conjunction with the model. The approach I therefore recommend is to start your design with querying in mind, but to avoid any premature optimisations that might constrain the set of possible queries. In this way, the domain can retain its potential to answer further interesting questions when new requirements are discovered.
There are obviously certain problem classes where all of this isn’t needed or is just overkill. In such cases you might choose to trade off power and flexibility for better immediate performance and operational characteristics. What is practical depends on the project, however the power of connectedness shouldn’t be overlooked or discarded lightly. In a world where it’s increasingly commonplace to use multiple persistence technologies alongside each other, choosing the appropriate model first and then complementing it with additional technologies to address any subsequent performance issues is probably a better option in the longer run.
Going back to Neo4j, it has been possible for a while now to implement robust and flexible graph-based applications with Neo4j. However, there has been a slight awkwardness in the programming model that stems from the gap between the graph paradigm and how business problems are traditionally represented. (For example, how do I map traversal logic to business logic? Or, if I’m writing a traverser, how do I assert that the result is a valid solution to my business problem?). In addition to that, the Java API itself has been going through a number of refactorings.
The approach I have been comfortable with thus far is to embrace the graph model and to consider it as the base domain, deferring any mapping to alternative models (such as DTOs) to the presentation layer. Thinking in terms of graphs when working with graphs might sound obvious, but it does require some adaptation effort.
The flow of new features and improvements in Neo4j has been kept steady and some of them have been substantial, such as the introduction of the Cypher query language last year. What prompted me to write this however is the latest roadmap announcement (and some coffee-machine conversations with the Neo4j guys 🙂 ), and the exciting direction that the Neo4j team seems to be taking.
There are a number of upcoming features that I find particularly interesting not only because of their intrinsic value, but also because of how they provide a natural model to implement powerful graph based applications. The most important of these is Labels. These give the ability to attach expressive tags to nodes and relationships of the same type, for example a node representing a person would be tagged with “Person”. While this is feature is highly valuable on its own (and has been a popular request for a while), it opens up the door for a couple of interesting possibilities.
First, a more powerful auto-indexing capability will be the norm whereby indexes are automatically created for nodes based on their labels. So a “Person” node could automatically be indexed by its “name” and “gender” properties. This should significantly simplify common indexing idioms that programmers regularly have to implement in Neo4j applications right now. The benefits would also extend to Cypher queries, effectively making them more expressive and providing a tempting opportunity to optimise query performance.
The other possible improvement – that hasn’t been confirmed as part of the roadmap yet – is the ability to express local constraints on certain nodes based on their types (or labels) again. For example, a “Person” node would always be expected to have a “name” property. It should then be possible to preserve the schema-less nature of the graph globally but to enforce at the same time stronger consistency where needed.
With Cypher approaching feature completeness and stable, improvements to performance would allow Cypher to become the first entry point to interact with Neo4j in a wider range of use cases.
To complete the picture, the addition of a binary protocol over the wire would allow Neo4j to finish the transition into an efficient and platform-agnostic server mode and to be perceived as a fully-fledged product.
I believe that all these features put together will allow Neo4j to reach its full potential by offering developers well defined concepts and an aligned programing model that are as familiar as traditional SQL. Ultimately, what is most exciting is the potential of graph-based applications themselves. While other NoSql technologies were initially conceived to solve specific classes of problems, a graph-based approach promises to address a large class of more general problems. Neo4j is still growing towards its potential in this regard, and I believe that it might well be just about to get there.
This blog is written exclusively by the OpenCredo team. We do not accept external contributions.
SHARE







NODES 2022 – Neo4j Online Developer Education Summit 2022 – Tracing your data’s DNA
As data becomes ubiquitous and deeply interconnected, tracing where who or which system that data comes from – its lineage – will create bigger problems…