January 11, 2018 | Data Engineering
The last few years have seen Python emerge as a lingua franca for data scientists. Alongside Python we have also witnessed the rise of Jupyter Notebooks, which are now considered a de facto data science productivity tool, especially in the Python community. Jupyter Notebooks started as a university side-project known as iPython in circa 2001 at UC Berkeley.

![]()
Its creator’s goal was to minimize the complexity of their data science stack, which at the time was a mishmash of programming languages and tools ranging from C++ to various Perl, bash, awk, and sed scripts. The idea was to use Python, or an interactive version thereof, as a replacement for that intractable stack, with the intention of improving productivity and collaboration.
Over time, iPython became the Jupyter Notebook, which in turn is set to become Jupyter Lab.
The Jupyter Notebook is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. Uses include: data cleaning and transformation, numerical simulation, statistical modeling, data visualization, machine learning, and much more.
jupyter.org
The end result of using Jupyter Notebooks is that you can write code in your browser, run it, and see its results, including visualizations, immediately and interactively. You can see a nice example of what this looks like in the open source Python Data Science Handbook’s.
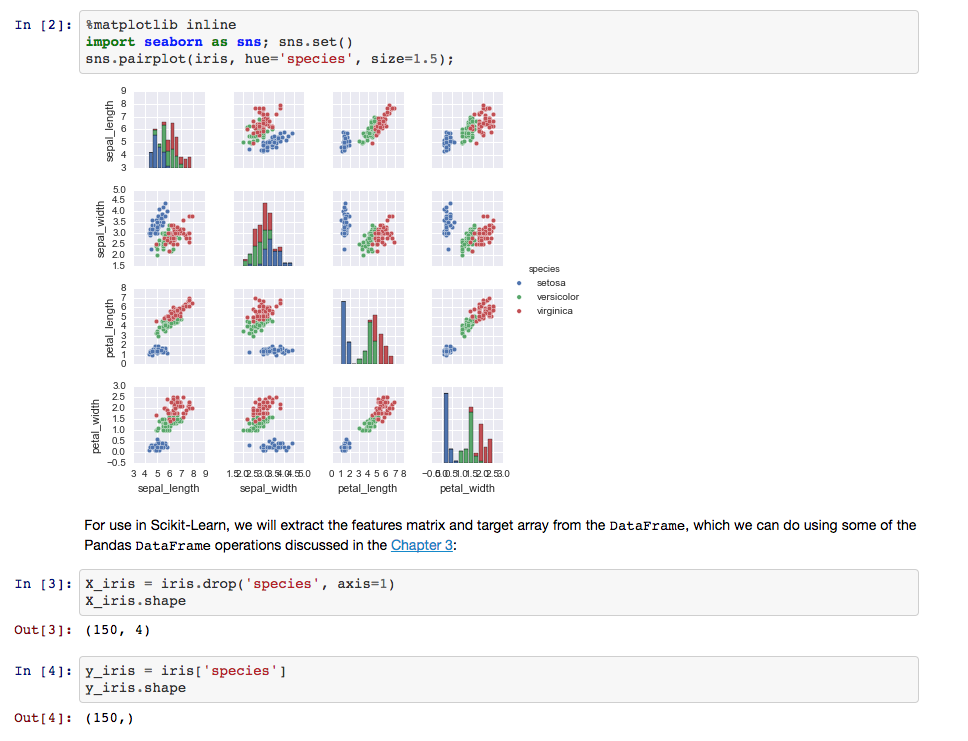
You can open and view the entire Notebook on your browser with the click of a button.
JupyterHub, in turn, is a multi-user version of the notebook designed for companies, classrooms and research labs. What it allows one to do is centrally manage the lifecycle of multiple Jupyter Notebooks. It has been used to deploy Jupyter Notebooks to students and researchers, sometimes in the thousands (e.g. for university Data Science or Statistics courses). This scalability, along with the modular architecture of JupyterHub, is proving critical towards making an enterprise grade piece of software out of a supremely popular open source project.
In particular, JupyterHub features pluggable authentication modules, allowing integration with e.g. existing LDAP structures, as well as custom Spawners that let you specify how and where to run the individual Jupyter Notebooks. For example, the notebooks could be configured to run as processes on a single machine, as Docker containers, or within a Kubernetes cluster. The Jupyter wiki features 11 such Spawners at the time of my writing which are generally supposed to work, each intended for different purposes.
One of the first things to understand before beginning to use JupyterHub (let alone writing a Spawner) is that it has two sides to it: the Hub itself, and the single-user Notebook servers it spawns. The Hub is your “server”, a tornado process fronted by configurable http proxy, which through configurable Spawners allows you to control the lifecycle of your Notebooks in different ways. In our case our custom Spawner is responsible for starting EC2 instances (we explain why and how further down) which in turn will each run a single-user Notebook server, which will need to sync up with the Hub.
It’s easy to get confused by the above, so let’s take a step back. A typical reader is likely to have used Jupyter Notebooks on their laptop in the past. If that’s you, and you’re not sure how Notebooks relate to the Hub, read on, this bit is for you. If you’ve never used a Jupyter Notebook on your laptop, you may want to give it a try before reading on. There are great getting started guides for beginners, so it should be fairly straightforward.
When you type jupyter notebook in your terminal, you will see something like this:
[I 16:58:36.008 NotebookApp] JupyterLab alpha preview extension loaded from /Users/alext/anaconda3/lib/python3.6/site-packages/jupyterlab
JupyterLab v0.27.0
Known labextensions:
[I 16:58:36.010 NotebookApp] Running the core application with no additional extensions or settings
[I 16:58:36.016 NotebookApp] Serving notebooks from local directory: /
[I 16:58:36.016 NotebookApp] 0 active kernels
[I 16:58:36.016 NotebookApp] The Jupyter Notebook is running at: http://localhost:8888/?token=92fdf4dc00b7cdcb10c7442fd85d54c9f0a34bb74beb7863
[I 16:58:36.016 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 16:58:36.017 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=92fdf4dc00b7cdcb10c7442fd85d54c9f0a34bb74beb7863
[I 16:58:36.120 NotebookApp] Accepting one-time-token-authenticated connection from ::1And this is what’s going on:
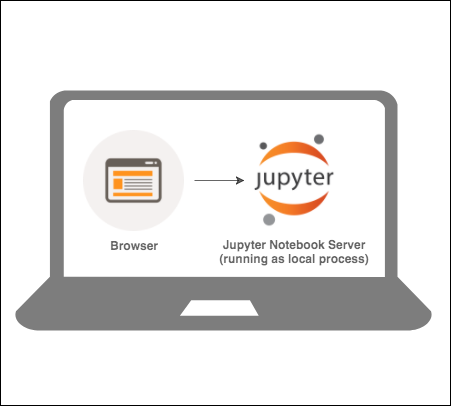
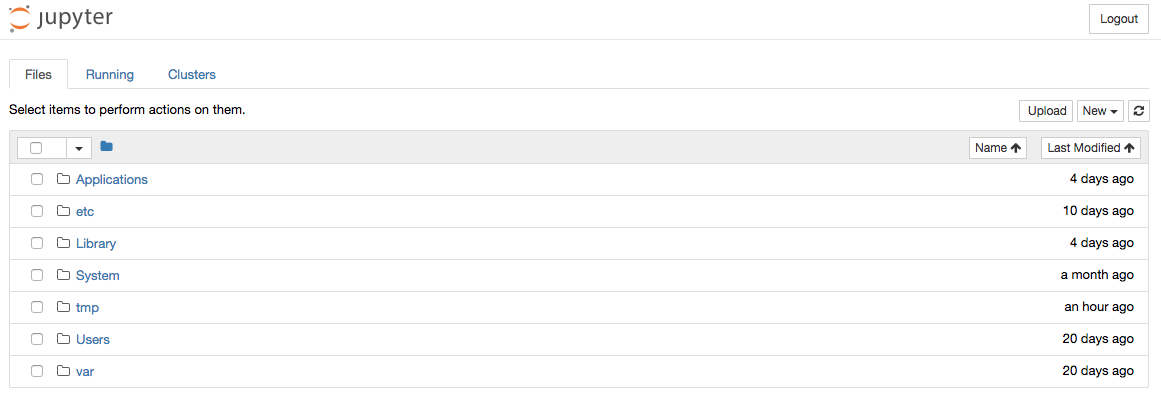
Your laptop is running a Jupyter Notebook Server locally, which serves some content that your browser can browse to on the URL (with the token). When you browse that URL you will see the main dashboard page, something like this:
Things are hopefully clear so far. Now we bring in JupyterHub (if you want to try to follow along, the documentation includes an installation and a getting started guide):
With JupyterHub you can create a multi-user Hub which spawns, manages, and proxies multiple instances of the single-user Jupyter notebook server.
https://github.com/jupyterhub/jupyterhub
Let’s imagine that instead of working locally on our laptops, we have 10 researchers, all of which need to be using Jupyter Notebooks. Instead of having each of them install and run Jupyter Notebooks locally, we set up a centrally accessible Linux machine (on premise or cloud) and install JupyterHub on it. After configuring it and starting it up, JupyterHub will be running and waiting for clients to request a new notebook. Things will look something like this (depending on your Spawner amongst others):
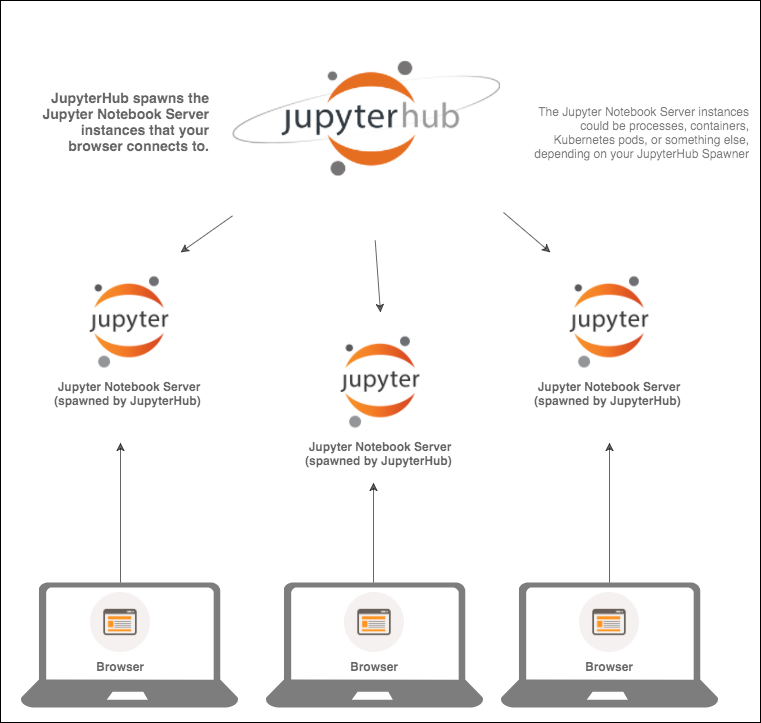
None of the laptops are running Jupyter Notebook servers now. The Jupyter Notebook servers are managed by JupyterHub. Instead of having to start a Notebook locally, users simply connect to a URL where the Hub is exposed, and get their own Notebook there. So the JupyterHub server starts Jupyter Notebook servers. Where these Notebook servers run depends indeed on your Spawner. As mentioned previously, the 10 Notebooks we need in this example could be 10 processes on the same machine, or 10 containers on the same machine, or 10 pods spread out over 3 Kubernetes nodes.
Recently as part of our involvement in a migration task for a client, we reviewed a collection of custom Spawners that had been written internally sometime in the past and were no longer maintained. Specifically, we needed to make sure that these old custom Spawners would work on our client’s new AWS infrastructure, and to make improvements in their behavior where possible. The scale of the work that the platform’s users were doing varied greatly. This meant that they needed an instance each; often times a large GPU instance. Instead of spawning Notebooks as processes or containers (which is what practically all Spawners in the wiki do), our custom solution needed to spawn a dedicated, appropriately sized EC2 instance, and then a single-user Notebook server on it.
In other words, given 10 users, we needed a Spawner that creates 10 Notebook servers on 10 fresh EC2 instances of custom type/size, and none of the Spawners in the wiki could do that. The varying scale requirements could reasonably be achieved using JupyterHub on Kubernetes, which happens to be a very well documented solution. In our case we had to rule Kubernetes out for different reasons.
Ultimately we decided to refactor the functionality of a number of the client’s existing bespoke custom Spawners into one Spawner. The main feature of this new Spawner was that it would allow the user to make a choice for the instance type/size they need, spin up that instance, and have them redirected to a Notebook running on that new instance. Once their work was done (i.e. once they clicked on the “Stop My Server” button, shown later in this post), the instance would shut down. This provided the researchers independence, was quick and straightforward (even more so than having to deal with auto-scaling and such), and was cost-effective (at least as long as the users didn’t aggressively overprovision).
The most basic Spawner, one which starts a single local process, would look like this (written in Python):
def start(self):
command = self.cmd + self.get_args()
env = self.get_env()
spawn(command, env)In other words, it would need to pass a series of commands, arguments, and environment variables, including credentials/tokens, to the single-user server so that it can authenticate back to the Hub. But how exactly do we use or call start()? To answer this question, here’s a quick overview of the JupyterHub workflow as far as its users are concerned:

stop() in the background).
That’s essentially all the user sees of JupyterHub, and it is this workflow that our custom Spawner needs to support. In general, a custom spawner will need to implement the following methods:
EC2Spawner:
@gen.coroutine
def start(self):
notebook_server_ip = yield self.start_ec2_instance() # that would be a function that uses boto3 to start an instance, pass it the dict from <code>get_env(), and return its IP return (notebook_server_ip, NOTEBOOK_SERVER_PORT)Note that the start() method is supposed to return an `(ip, port)` tuple, as it does here. All we’re doing here is starting an EC2 instance. We should also save the EC2 Instance ID of the instance we just started (again, using boto3), as we would like to pass this to get_state() (see below). We can take care of starting the Jupyter Notebook Server and authentication later.
@gen.coroutine
def stop():
try:
stop_ec2_instance(self.ec2_instance_id) # function that uses boto3 to stop an instance based on instance_id
except Exception as e:
print("Error in terminating instance " + self.ec2_instance_id) # easy to save the instance id when you start the instance
print(str(e)) # this will print the error on our JupyterHub process' output`None` if it is, or the exit code if it has errored out, or `0` if the exit code is not known.The 3 methods above need to be coroutines. You will also need the following two (which shouldn’t be coroutines):
def get_state(self):
"""get the current state"""
state = super().get_state()
if self.ec2_instance_id:
state['ec2_instance_id'] = self.ec2_instance_id
return statestate['ec2_instance_id'] that get_state() previously wrote).You can find more commentary on the 5 functions discussed here in the various custom Spawners from the wiki. Personally I found the code in the Marathon Spawner very clear, so if you want to see a good example of these in real world code, check out the Marathon Spawner on Github.
Whilst we are unable to provide the exact code and full implementation at this stage (there are some ongoing discussions about open sourcing this Spawner), we have tried to share our initial experience as well as the broad set of steps and considerations required to build a custom Spawner.
To summarize, in order to achieve the functionality we wanted, we needed to implement a method that starts and a method that stops an EC2 instance. Both were easily achieved with the AWS Python library boto3. The healthcheck (poll() method) was also relatively straightforward due to the fact that the single-user server exposes an HTTP interface; since we were starting an entire instance as opposed to a process, or a container, we needed to provide a lot more “initialization time” than most other Spawners (can start from something like this “waiting” function). State management was also not too complicated and in fact the example we showed above would serve you quite well.
Finally, as mentioned already, we needed to pass a number of arguments/parameters/credentials to the new instance. Most of these are generated by JupyterHub and exposed via the get_env() method, but you can also pass further optional data of your choice. There are various ways to pass this information to the new instance, but I opted for user data (which is a way to execute commands or scripts right as an instance starts). The fact that we were able to control how our EC2 instance is started means we had a lot of flexibility in configuring it, e.g. starting instances in different accounts based on the user’s identity. With the basics taken care of, the next considerations were authentication and health checks. In a future post we may show how we chose to implement the above, dive deeper into Spawner internals and provide more details on how we fulfilled our overall requirements.
As a final note, the community around JupyterHub is absolutely top notch. Check out the JupyterHub gitter channel where folks are extremely helpful, and feel free to ask any JupyterHub related questions you may have. Special shoutout to @minrk who is both supremely knowledgeable and generous with his time.
This blog is written exclusively by the OpenCredo team. We do not accept external contributions.
SHARE





GOTO Copenhagen 2023 – The 12 Factor App For Data (Recording)
Watch the recording of our Technical Delivery Director, James Bowkett from the GOTO Copenhagen 2023 conference for his talk ‘The 12 Factor App For Data’

