September 20, 2015 | Microservices
Over the past five years I have worked within several projects that used a ‘microservice’-based architecture, and one constant issue I have encountered is the absence of standardised patterns for local development and ‘off the shelf’ development tooling that support this. When working with monoliths we have become quite adept at streamlining the development, build, test and deploy cycles. Development tooling to help with these processes is also readily available (and often integrated with our IDEs). For example, many platforms provide ‘hot reloading’ for viewing the effects of code changes in near-real time, automated execution of tests, regular local feedback from continuous integration servers, and tooling to enable the creation of a local environment that mimics the production stack.
![Microservice Platforms: Some Assembly [Still] Required. Part Two](https://opencredo.com/wp-content/uploads/2018/10/banner-services-895x196.jpg)
If we look at a typical build pipeline for a monolithic application we can see that the flow of a single monolithic component is relatively easy to orchestrate. The pipeline obviously gets more complex when we are dealing with microservices, and we’ll cover this in future blog posts, but for now we will look at the pre-pipeline local development phase that will most likely involve working simultaneously with multiple dependent services.
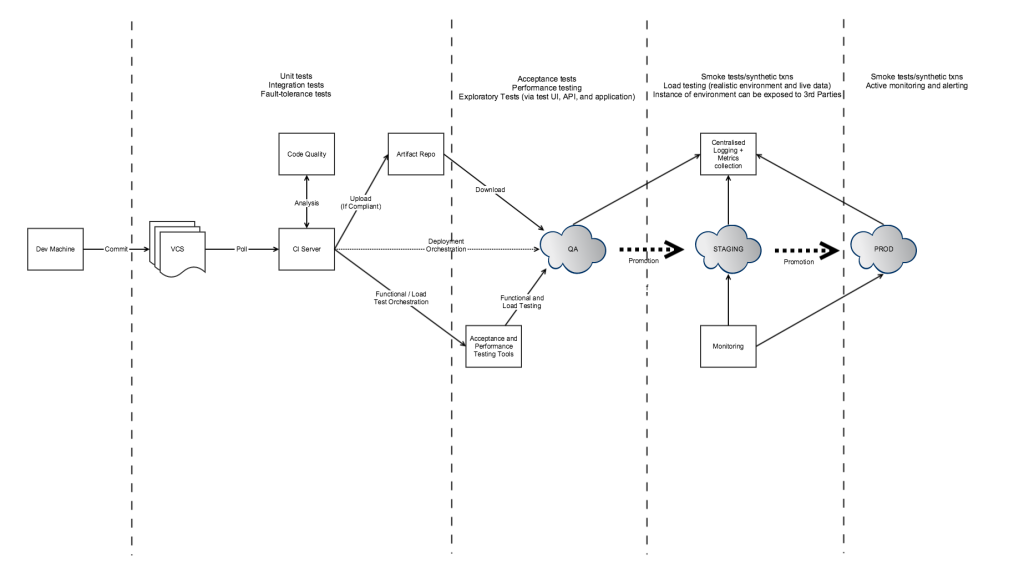
When working with a monolithic codebase we should be able to assume that the creation and configuration of a local development machine is as least as easy to configure as a QA environment (and if it isn’t, then you should be asking why!). Local developer machine configuration tooling such as Github’s Boxen (Puppet), Pivotal’s Sprout (Chef), or mac-dev-playbook (Ansible) allow us to specify the installation of local tooling and standardise configuration, or alternatively virtualised local environments through the use of Vagrant or Docker Compose (née Fig), are relatively easy to set up for a single stack.
Within the world of microservices the tooling for these development tasks often exists at a component/service level, but things get a lot more challenging when the number (and variety) of services increases, the number of dependencies between services increases, or when a complex business workflow takes place at a higher (system) level that involves several coordinating services.
In my experience, when most developers start working with microservices they simply attempt to replicate their local development practices for each new service. I believe this is a logical approach (and I’ve done it!), but as with many things within computing – manual replication only gets you so far.
The biggest problem I have encountered with this style of working is the integration costs of testing. Even if each service has integration/component-level testing, it can be very difficult to coordinate test configuration and initialisation once you develop more than a few services. You’ll often find yourself spinning up an external service locally (by cloning the code repository from VCS, building and running), fiddling around with the state, running tests on the service code in which you are developing, and finally verifying the state of the external service.
In the past I have seen many developers attempt to overcome this problem by creating simple scripting files (bash, python, ruby etc) that wire everything together and initialise data for tests. In my experience this quickly becomes a nightmare to maintain, and isn’t a recommended approach – I only include it here as a baseline, and so read on to learn about a scalable approach…
If you are familiar with developing code using the JVM-based Spring framework (or the maven build tool) you will instantly recognise the concept of ‘profiles’, but this pattern in present across many language stacks (e.g. Rails’ ‘RAILS_ENV’ or Go’s envconfig). Essentially profiles allow multiple configurations to be developed and switched at build or run time. This will allow you to develop mock or stub implementations of external service interfaces for local development, and switch this version and the actual production implementation as required.
I have used this technique with great success when developing a Java-based ecommerce ‘shop-front’ service that was dependent on a ‘product-search’ service. The interface for the product-service was well-defined, and we developed several profiles for use when running automated tests via maven/rake:
Although not exactly stubbing or mocking, I’m going to also include the use of embedded or in-process data stores and middleware within this pattern. Running an embedded process will typically allow you to interact with this component as if you were running a full out-of-process instance, but with much less initialisation overhead or the need to externally configure the process. I have had much success with using H2 as a test replacement for MySQL, Stubbed Cassandra for Cassandra, and running an embedded ElasticSearch node.
When mocking or stubbing external services becomes complex this can be the signal that it would be more appropriate to virtualise the service (and as an aside, if your stubs start to contain lots of conditional logic, are becoming a point of contention with people changing pre-canned data and breaking lots of tests, or are becoming a maintenance issue, this can be a smell of too much complexity).
Service virtualisation is a technique that allows us to create an application that will emulate the behaviour of an external service without actually running or connecting to the service. This technique allows for the more manageable implementation of complex service behaviour that mocking or stubbing alone. I have used this technique successfully in a number of scenarios, for example, when a dependent service returns complex (or large amounts of) data, when I don’t have access to the external service (for example it may be owned by a third-party or is run as a SaaS), or when many additional services will interact with this dependency and it will be easier to share the service virtualiser than mock/stub code.
Tooling in this area includes:
This pattern enables a developer to download pre-canned images of services to a local machine that can be easily executed for development against or for running tests. We started doing this initially with HashiCorp’s Vagrant, where we could create a preconfigured vbox image that contained an application’s code/binaries alongside an OS, configuration and associated data stores, which was shared around the development team. The arrival of Packer made the image creation process even easier, and also gave us the ability to specify application packaging once, and re-use this across environments (e.g. AWS in production, OpenStack for QA, and VirtualBox for local development).
Arguably the arrival of Docker massively promoted this style of application packaging and sharing, and the Fig composition tool was the icing on the cake. Fig has since evolved into Docker Compose, and now allows the declarative specification of applications/services and associated dependencies and data stores. This pattern does allow for the very flexible execution of a collection of dependent services on a local development machine, and the main limiting factor in our experience is machine resources (particularly when running hypervised platforms).
The ‘production-in-box’ pattern also allows us to keep a much cleaner local developer environment, and also removes potential configuration clashes by encapsulating a service and its dependencies and configuration (e.g. different requirements of Java version). We can also parametrise the images (through initialisation params or environment variables), much like we did with the ‘profiles’ pattern above, and allows services to behave as we require. We have successfully used Docker plugins for both maven and Ruby/Rake, which enable the integration of container lifecycles with test runs.
A potential extension to this pattern is developing within the actual images themselves, for example by mounting local source code into the running instance of an image. If done correctly this can remove the need for the installation of practically all tooling on the local development machine (except perhaps your favourite editor or IDE), and greatly simplifies the build toolchain (e.g. you don’t have to worry about GO_PATHS, or what version of Python you are running). If you are running a compiled language then it is possible to create a dev and production image via a build pipeline, which contain the source code or only the linked binaries respectively.
In a nutshell the environment leasing pattern is implemented by allowing each developer to create and automatically provision their own remote environment that can contain an arbitrary configuration of services and data. The services and data (and associated infrastructure components and glue) must be specified programmatically via Terraform or one of the CAPS tools (our current favourite is Ansible) and the knowledge shared across the team for this approach to be viable, and therefore you must be embracing the DevOps mindset. A local development machine can then be configured to communicate with dependencies installed into the remote environment as if all the services were running locally. We have used this pattern when deploying applications to cloud-based platforms, which allows us the spin-up and shutdown environments on demand.
The ‘platform leasing’ pattern is an advanced pattern, and does rely on the ability to provision platform environments on-demand (e.g. private/public cloud with elastic scaling), and also requires that a developer’s machine has a stable network connection to this environment. We have also found running a local proxy, such as Nginx or HAProxy in combination with HashiCorp’s Consul and consul-template, or a framework such as Spring Cloud in combination with Netflix’s Eureka,is useful in order to automate the storage and updating of each developer’s environment location.
This article has attempted to summarise our learnings over the last five or so years of locally developing and working with microservice, and is part of our “Microservice Platforms: Some Assembly [Still] Required” series. Working locally with one or two services is easy enough with existing tooling and approaches, but in our experience the complexity of orchestration and configuration increases exponentially with the number of services developed unless we utilise the patterns documented above.
In addition to the descriptions of the local development patterns above, I have also included a PDF ‘cheat sheet’ of the details, which can be downloaded below:
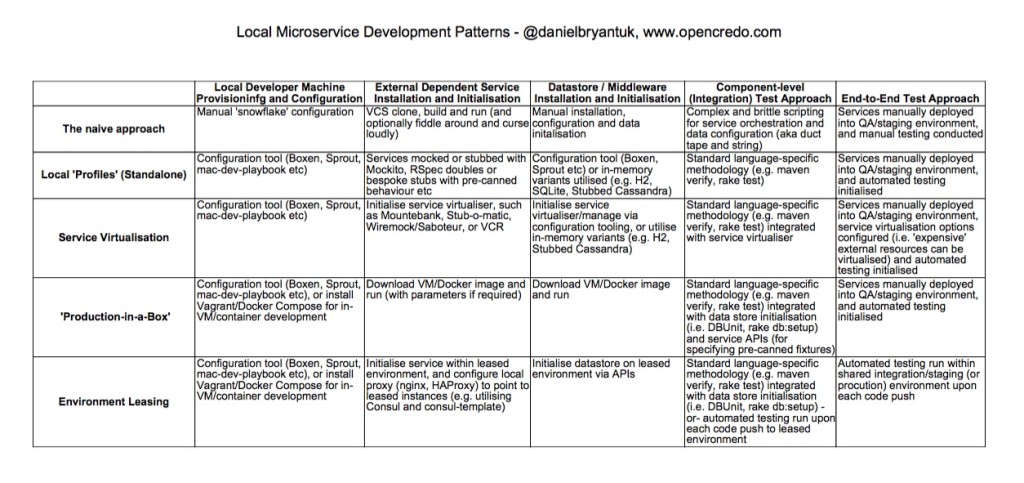
Local Microservice Development Patterns – @danielbryantuk, www.ocwww.wpengine.com – Sheet1
You can read more about our learnings with developing microservices platforms on our blog, including microservice patterns, “things I wish I’d known before I started with microservices”, and the “seven deadly sins of microservices”.
OpenCredo are also hosting a free webinar this week that explores “The Business Behind Microservices”.
Please join us!
This blog is written exclusively by the OpenCredo team. We do not accept external contributions.
SHARE







