January 25, 2017 | Cassandra
One of the simplest and best-understood models of computation is the Finite State Machine (FSM). An FSM has fixed range of states it can be in, and is always in one of these states. When an input arrives, this triggers a transition in the FSM from its current state to the next state. There may be several possible transitions to several different states, and which transition is chosen depends on the input.

We can represent a simple FSM with a graph showing the states, inputs and transitions, like so:
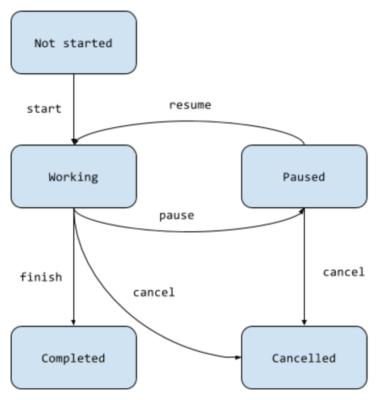
This represents a task which can be started, paused, resumed, finished and cancelled. It is always in one of its five states, “Not started”, “Working”, “Paused”, “Completed” or “Cancelled”. Not all of its possible inputs are valid in all of its possible states: one cannot pause a process that has completed, for example, or resume one that is already working.
FSMs are completely deterministic, so that given a starting state and a sequence of inputs the FSM will always arrive at the same state after every input has been processed. For example, if we begin in the “Not started” state, and accept the sequence of inputs “start, pause, resume, pause, cancel” we will always end up in the “Cancelled” state. Another way to say this is to say that the state of an FSM is a function of an initial state and a sequence of inputs.
In a similar way, in a SQL database system, the total state of the system – the content of its tables – is a function of an initial state and a sequence of transactions. Given a snapshot of the database, and a log of transactions that have occurred since the snapshot was taken, one can arrive at the current state of the database by re-running the transaction log against the snapshot. Each transaction moves the database from one valid and consistent state to another: it determines a state transition. Obviously the states of a database system are much more complex than those of the graph shown above, and there are vastly many more possible states, but the total number of possible states is still finite, as is the total number of possible transitions.
A distributed system is one in which separate parts of the system operate according to their own independent schedules, and communication between connected parts of the system is subject to unpredictable loss and delay. Multiple computers in an ethernet network are one example of a distributed system. Strictly speaking, a single computer is also a distributed system (CPU and RAM are physically separate-but-connected, for example), but it is one that is made to behave as much like an FSM as possible by synchronising the activities of its separate parts. We work with a highly simplified model of the behaviour of a single computer in which machine code operations read values from memory into registers, transform these values in various ways, and write them back into memory without (for the most part) observable non-determinism: the machine moves predictably from state to state.
Whenever we try to extend the FSM model of computation to a distributed system, one of two things will happen. Either the model will break down, because the overall behaviour of the system cannot be modelled deterministically; or the system will have to be synchronised in order to ensure that it continues to behave in a coherent way. Mechanisms such as distributed transactions are ways of synchronising the behaviour of distributed systems, making them behave more predictably: they aim to ensure that a change which affects multiple parts of the system looks like it has occurred as a single transition from one overall state of the system to the next.
Synchronisation mechanisms such as these make the behaviour of distributed systems easier to reason about, but they come at a cost: multiple resources have to be co-ordinated, and everything must move forwards at the pace of the slowest-moving part. When we want to build a highly-scalable system with many moving parts, in order to take advantage of the parallelism this affords, then distributed transactions and other global synchronisation mechanisms are a performance-killer. Usually the trade-off we have to make is between demarcating regions of consistency, within which our system behaves more or less like an FSM, and allowing separate regions to proceed without synchronisation, using alternative patterns for co-ordination and communication. The art of distributed systems architecture is all about understanding these alternative patterns and applying them judiciously.
Events arrive at the boundary of a distributed system, and eventually (in theory) that system’s internal state will faithfully reflect everything that has happened to it. Between the outermost boundary and the innermost, most authoritative record of the system’s state – it’s persistent data store, or “source of truth” – distributed processing occurs. If we cannot model this processing as a series of transitions in a state machine, then how should we model it? What metaphors might be useful in picturing the way that new information in such a system becomes settled knowledge?
In the rest of this post, I’m going to present a way of dividing the behaviour of a distributed system into separate “strata” representing different processing schedules. The general idea is that the patterns and technologies that are appropriate for one stratum may not be appropriate for another. These strata may cut across parts of the system that we would otherwise consider as units, for example individual services in a microservices architecture. At the same time, parts of the system belonging to the same stratum may share a common “fabric” which enables co-ordination and communication between them. This way of looking at the system is thus orthogonal to the kind of modular or regional decomposition (e.g. into “bounded contexts”) which most people associated with microservices architecture – a perspective organised around “cross-cutting concerns” which are not typically foregrounded in domain analysis.
With apologies to any neuroscientists reading, I’d like to draw an analogy between three kinds of “memory” in a distributed system, and three kinds of memory involved in human cognition. Human beings have short-term memory, which we use to keep track of the current state of things around us, medium-term memory, which we use to reflect on and reason about recent events, and long-term memory, which acts as a permanent (if somewhat lossy and unreliable) record of things which have happened in the past.
Our short-term memory is fast, transient, and limited: we can only keep so much in our heads at once, and a blow to the head or a few large whiskies can result in total short-term memory loss. It’s the kind of memory we need to have when crossing the road, in order to remember when looking right that we didn’t see anything coming when looking left, or when we’re holding a conversation with someone who’s imparting a stream of socially-significant information and we need to remember who’s reported as having said what to whom. In general, its purpose is to support us in reacting appropriately to whatever is happening in front of us right at the moment.
The transient memory of application processes is like this: fast, volatile, limited, and used to keep track of immediate processing or session state, as well as cached data we’ve pulled out of some longer-term storage and kept around in case it needs using again soon. It will disappear for good if the process has to be restarted. Multiple separate processes can share the same transient memory by making use of grid-based storage such as Hazelcast or Apache Ignite, so that what is remembered by one process instance is available to all, and replicated among grid-participants for greater resilience. This is one way to implement things like shared idempotency filtering, which detects duplicate inbound messages, in a distributed environment.
Our medium-term memory enables us to keep recent events in mind so we can chew them over, think about the consequences of what has been happening, sort and evaluate and narrativise. It’s the memory we use for reasoning (in a broad sense, which would include emotional processing), and it enables multiple aspects of our cognitive environment to pitch in and have their say. The analogous type of storage in a distributed system is the kind of log-structured buffer offered by technologies such as Apache Kafka. Information held in the buffer is available to multiple consumers, all processing it at their own separate pace, which can drive downstream analytics, populate indexes, detect when alert thresholds have been reached, and generally update their own view of the world based on new information. Although the information held in the buffer will eventually expire from it, it is kept around, persistently, typically for several days.
The long-term memory of human beings is our “source of truth” about what has happened in our lives. One important difference is that human memory is notoriously unreliable, whereas we have designed our persistent data stores so that we can trust them not to lose, corrupt or subtly rewrite the facts we record in them. Our databases remember things for us wholesale. Another difference is that in conventional use, databases allow the information recorded in them to be modified, so that they maintain an up-to-date representation of the current state of the world. However, when a wide-column store such as Apache Cassandra is used in an append-only fashion as a permanent record of accepted events, then it becomes something more like a “long-term memory” of the system.
We can thus identify three kinds of storage in a distributed system, corresponding to the three kinds of human memory: transient, buffered and persistent. To these kinds of storage correspond three different types of processing: reacting, reasoning and remembering, the “three ‘R’s” of my title. Transient storage is used by service instances to determine how to react appropriately to incoming information; buffered storage is used by log consumers to “reason” about events, implementing the deeper logic of the system; persistent storage is the system’s source of truth about what has happened in the past.
In “orthodox” architectures a few years ago, it used to be that the database contained almost the only shared state of the system: individual processes might have their own transient memory, and message brokers might temporarily persist messages on their way to delivery, but it was held to be good architectural practice to keep everything above the database layer as “stateless” as possible. What happens when we introduce grid-based memory and log-structured event publishing to a distributed system is that shared state once again becomes part of the picture at other layers of the system. Each “unit” deployed within the system is embedded in a “fabric” that enables it to share the kind of state appropriate to each type of processing it performs with other units.
At the level of transient, short-term storage this means distributing cache and “working state” data within a shared data grid, so that individual services do not need to go to the database to find out whether the message they have just received is a duplicate of a message that has already been processed (this is the purpose of a distributed “idempotency filter”). Requests to update small pieces of transient data can be routed to the nodes where that data is held, and processed atomically there. Because the data at this level is volatile and might always disappear completely (for example if the entire grid is restarted), it must always be handled using cache semantics: data not found in the cache must be reliably retrievable from elsewhere. This has the further advantage that the total size of data in the grid can be kept within fixed bounds.
One particularly powerful use of grid memory is to implement the “claim check” pattern in dispatching messages between services. A large message can be broken up into its constituent parts, and these parts cached in a distributed map in grid memory. A smaller message consisting of references to the cached parts is then dispatched to consumers, and each consumer retrieves the parts of the message it is concerned with from the cache (or, failing that, from the originating service, which must be able to reproduce it on demand). This significantly reduces the size of messages passing through the message broker, and saves each consumer the burden of deserialising content which is irrelevant to its purposes.
Buffer-level storage is particularly useful in maintaining “query-optimised views” of persisted data. Each part of the system that wishes to record something in the persistent store instead writes it into a Kafka topic. One consumer then updates the persistent store, while others update indexes and query-optimised views, enabling query patterns that the persistent store is not designed to service. The processing guarantees provided by Kafka, which offers at-least-once delivery of every message it acknowledges, mean that data written into the buffer can be treated as “as good as” persisted even if it isn’t written into the persistent store immediately. (If a client needs to know for certain when persistence has completed, then the persisting consumer can write a message into another topic). An important thing to understand about the “shared state” in buffer-level storage is that it is immutable: there is no risk of contention between different consumers trying to update the same data, because consumers can never modify entries in the buffer once they have been written.
A consequence of introducing shared transient and buffered state into the system is that the persistent data store ends up having less work to do in coordinating the behaviour of the various pieces higher up. It is the “source of truth” about the past, but is less involved in the affairs of the present. This becomes especially important when a distributed database technology such as Cassandra is chosen for this purpose, as Cassandra itself cannot provide coordination mechanisms such as ACID transactions to its clients, and supports only a limited range of query patterns. Other parts of the system must step in to orchestrate behaviour, resolve contention over shared resources, and provide query-optimised views. The traditional functions of an RDBMS do not vanish entirely from a system using Cassandra, but rather migrate to different parts of the system to be implemented, where needed, in different ways.
This blog is written exclusively by the OpenCredo team. We do not accept external contributions.
SHARE







