February 11, 2022 | AWS, Cloud, GCP, Kubernetes, Microservices, Open Source, Software Consultancy
Serverless functions are easy to install and upload, but we can’t ignore the basics. This article looks at different strategies related to testing serverless functions.

This blog was first published on DZone
Serverless computing, or functions-as-a-service, has picked up a lot of attention and speed due to its cost-effective pay-as-you-go price offering, multi-language/runtime support, as well as its easy learning curve without any need to provide the infrastructure layer. All the major cloud providers now have a serverless computing offer as part of their services portfolio: Amazon Web Services has Lambda, Microsoft Azure has Azure Functions, and Google Cloud has Cloud Functions. Furthermore, there are on-prem/on-Kubernetes options for running serverless functions on OpenWhisk or OpenFaaS. For the sake of consistency, I will refer to all of these services as serverless functions throughout the rest of this post.
In a microservices (or even nanoservices, as serverless functions are sometimes known) architecture, there are inherently lots of components, modules, and services that form part of an application or platform. This can make testing a chore, and sometimes a neglected part of the SDLC for these platforms. This article will explore some options and techniques for testing these types of platforms to help make this aspect of your projects easier. Testing should always be a first-class citizen, regardless of the infrastructure. Irrespective of the language, framework, or tools we use, testing is vital to ensure both sustained development velocity and the quality of our deliveries to production.
Writing serverless functions should also adhere to these same practices. Serverless functions focus on building functions as microservices. It should be easy to write test cases around the function code, but the ability to turn up with code and just run it (and scale it) in the cloud is very appealing. As a result, it can be tempting to cut corners in the engineering discipline, as the cloud-native element along with the burden of setting up a separate environment and deploying functions purely for testing can lead many people to just upload the code package directly, and maybe test manually at the cost of repeatability and quality.
In this post, we will walk through a number of approaches and techniques for testing your serverless functions.
In his 1981 seminal book “Software Engineering Economics,” Barry Boehm published some statistics on how the cost of making software changes or fixing bugs increases significantly over time, depending on the stage the software is in. The curve is still valid today, even forty years after it was first published.
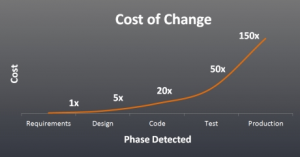
Figure 1: Cost of changes at different phases of the software lifecycle
All too often we see projects and platforms that either skip testing or contain inadequate tests in order to focus on the delivery of features. In the case of serverless functions, many developers usually deploy the function in the cloud and test it there, mainly to avoid the additional effort required to write effective test cases.
While you do save time by not writing test cases, this is often a false economy: it usually leads to a longer delivery cycle and has the obvious risk of introducing unexpected bugs or behavior in production.
In order to best support continuous delivery, it’s important to favor as much automation as possible, especially in the area of testing. Consider the traditional testing pyramid:
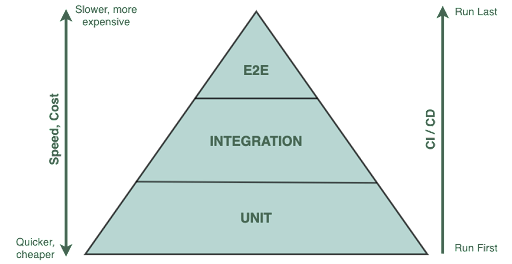
Figure 2: Traditional testing pyramid (Source: Succeeding with Agile by Mike Cohn )
While broad unit test coverage is undoubtedly important, it is integration and end-to-end testing that we will focus on here because this is where the various components within an application meet for the first time, especially in a distributed application. The line between integration tests and end-to-end tests is often blurred, as end-to-end tests can be considered a more complete form of integration tests.
When serverless functions become part of the landscape, every developer has to deploy a version of the function(s) under test to the cloud, which could be costly, untidy, or challenging to manage if each developer requires a separate environment. If this is the case within a non-cloud-hosted CI environment, then it potentially adds a new or additional external cloud dependency into a CI pipeline. CI pipelines need to be dependable and repeatable and as bullet-proof as possible, so often people either skip the integration testing for serverless or they mock out the functions in some other way. However, there is an alternative solution.
Although deployment and running of serverless functions are straightforward (either manually or using infrastructure as code), using deployment pipelines is always to be encouraged for the purposes of repeatable (and labeled) builds. The two should not be considered mutually exclusive.
Take the popular open-source Serverless Framework from Serverless Inc. and the AWS framework Serverless Application Model (SAM) for example. Both are slightly different in their approach to defining serverless functions, but their core idea remains the same when it comes to testing, packaging, and deploying.
Both the Serverless Framework and AWS SAM provide CLI commands to invoke a function locally.
To invoke a Lambda function locally with Serverless Framework:
serverless invoke local --function functionName
To invoke a Lambda function locally with AWS SAM:
sam local invoke [OPTIONS] [FUNCTION_LOGICAL_ID]
You may not want to start interacting with a real or production service while executing or testing your functions locally.
The Serverless Framework provides a plugin, Serverless Offline, to simulate the API environment locally so you can develop and test your functions faster.
Similarly, AWS SAM also provides the commands to locally stimulate the AWS API and functions environment.
The 3 main cloud providers all provide a similar way of deploying serverless functions locally:
This means they can be run within a CD pipeline on your local and non-serverless/non-cloud-native infrastructure. Often they can be run within a Docker container, as long as the design of your code is sympathetic to this feature (for instance, by getting downstream endpoint addresses from a config file that you specify at runtime, allowing you to swap between a test/local deployment and a production deployment).
Alternatively, if a vendor-neutral stance is required to test a serverless function, the same strategy can be employed by installing and running either the OpenWhisk or OpenFaaS framework within your CI environment. This allows you to spin up your serverless function and run it within a Docker container without incurring any overhead or cost of deploying it to a vendor-specific cloud-native serverless platform. The documentation for this from OpenWhisk is available here and for OpenFAAS here.
Alternatively, you could choose to wrap your individual functions in individual Docker containers and create a docker-compose file that exposes all of the different functions as separate endpoints. Again, the serverless implementation should be sympathetic to this and not rely on cloud-native configuration mechanisms. Instead, the functions should retrieve their config from a file specified at runtime (always favour files over runtime environment variables so they may be specified and deployed as code).
It’s a good idea to provide an entry point in each Lambda to ensure each can be easily and consistently run locally (e.g. the main method in Java, or some executable code in Node when the source file is loaded). You may choose to do this with a custom in-house library, or by function inheritance from a common superclass (or similar). Either way, make it consistent because then any wrappers you write will be reusable for other serverless functions.
As with non-serverless coding, the ports and adapters (aka hexagonal) design idiom should be used to separate the business/core logic from the incoming and outgoing communication mechanisms. You should aim to encapsulate your logic in a class/file or set of classes/files that knows nothing of any transport mechanisms like HTTP or message queues, etc. This allows the business logic to be easily unit tested using appropriate mocks and input values.
It’s a good idea to ensure that every serverless function (and indeed, every remote call regardless of the architecture) always yields a result, a value, or an error. A good way to do this is to structure your responses as follows:
{
response_code: 0 | -1 | 255,
response_payload: “exception trace or success message”
}If a serverless function always returns a result whether in success or failure then you won’t need to write tests that await a timeout and you can test more synchronously, and your CI pipeline becomes less flaky and more dependable.
Once your application passes your integration tests, deploy your labelled build into an environment. This could either be a hosted version of a docker-compose containing all your serverless functions running in any of the environment types outlined above, or some newly-provisioned cloud-hosted serverless infrastructure (by running your terraform, or similar within your pipeline). Use automation to install your serverless functions, then run your testing framework against the newly-built environment.
It’s a good idea to create automated release notes for a build, in case of any failures in your integration/end-to-end test suite. This gives your team a chance to figure out what was included or changed in the build since its last successful run. This is especially important with larger estates and team sizes.
Once you have a successful end-to-end run, you are then free to promote to your higher environments, either gated by automation or by manual promotion — depending on your stakeholders’ views.
Once you promote, it’s also a good idea to run a subset of your end-to-end tests (or a dedicated smoke test) as a post-deployment check, this could be done prior to a switchover (if you’re doing blue-green deployments), or could be achieved by having blessed values for inputs that each function understands, that signals that they should maybe respond with a test output, or store a result in a test results area, rather than perhaps doing “the live/production thing” that could have negative consequences for your stakeholders or — worse — your customers.
Serverless infrastructure is experiencing increasing adoption. The idea of serverless infrastructure is to own (and manage) less, delegating these responsibilities to purpose-built services.
Even though manual deployment is quick and easy with serverless platforms, the same infrastructure-as-code, SDLC practices, and rigor should be applied as we would a traditional application stack. We should still apply our usual best practices to writing, testing, and deploying serverless functions. We should design test cases that cover all parts of our application logic. We should also use tools that can help us simulate the production environment — be that locally, on-prem, or within CI pipelines (wherever they live) — to ensure we deploy these changes through our CI and CD pipelines into production securely and safely and to ensure continued delivery of high-quality software components.
This blog is written exclusively by the OpenCredo team. We do not accept external contributions.
SHARE






Lunch & Learn: Secure Pipelines Enforcing policies using OPA
Watch our Lunch & Learn by Hieu Doan and Alberto Faedda as they share how engineers and security teams can secure their software development processes…
