
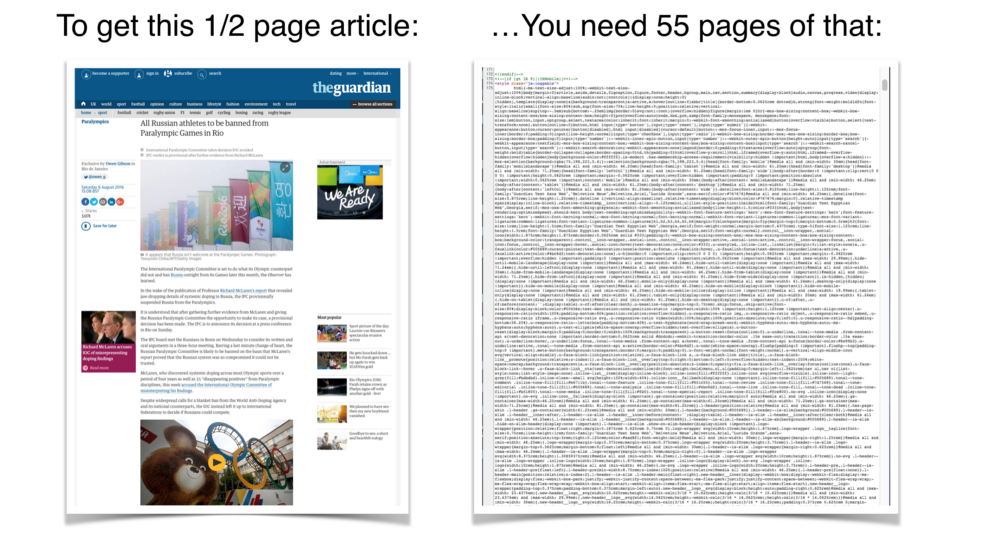
In this article, I argue that programmable infrastructure is similar to software, and needs testing too. I describe some of the unique challenges the industry faces in adopting infrastructure testing: both cultural and technical. I end by pointing out where we can go from here: we need to talk about it more, identify best practice, and improve our tooling.
What do we even mean by programmable infrastructure? It often gets mixed up with DevOps and other similar concepts. Here’s one definition:
Programmable infrastructure is the application of methods and tooling from software development to IT infrastructure
We can apply the lessons we’ve learned in software development, but apply it to a brand new field. In practice this means activities like:
But there’s a software development method that’s not in common use. Testing.
Almost all software becomes complicated over time. Everyone starts off with a simple codebase. By the time you’ve added all kinds of enhancements to it, it’s no longer so simple. The fact is, programming sucks.
That’s where testing comes in. Testing mitigates the effects of an application’s complexity. It gives us the confidence to make changes and detect regressions. It also mitigates risk. If you’re worried about the effects your code changes will have, your tests can catch them before they cause any damage.
This photograph below shows a firebreak. It is a strip of forest with no trees in. They’re used to prevent the spread of forest fires.

If a forest fire starts, it cannot cross the fire break. It acts as a barrier, and contains any damage. I like to think of testing like this. Failing tests prevent bugs passing into our production environment. Again, the damage is contained.
We’re used to testing applications like this. It is much rarer to test our infrastructure code. And infrastructure gets complicated! Once we start adding autoscaling, microservices, blue greening… our elegant, clean code gets way out of hand. If we apply the firebreak analogy, this could be common:

Our applications depend upon infrastructure to run. If our infrastructure has bugs, then your application will have issues too. Even the most extensively tested application will crash and burn due to an infrastructure issue. With tests, then you can control the damage, and do something about it quickly.
My personal experience – and from asking others in the industry – is that it’s rare! The most common activity is a manual check, rather than an automated regression suite.
If we want this kind of testing to become more common, there are some unique challenges we have to face up to.
Some years ago, I was a physics teacher. Physics is hard, and requires decent maths ability. Many students struggled applying mathematical techniques. But these techniques were more simple than those in their maths classes! In their heads, they were maths techniques – not physics techniques. They didn’t think to apply the same knowledge, because they were in a different classroom.
I see the same issue with testing infrastructure. I’ve seen talented developers not follow standard development practice when writing infrastructure code. We don’t solve the same issues in the same way!
Additionally, DevOps has brought a lot of new talent into development teams. Many ex-sysadmins now work alongside developers and testers. They have not come from a background where automated testing is the norm. But that’s okay! We often forget that it took decades for testing to become common practice for developers. One of the benefits of cross functional teams is that we can learn from one another.
DevOps is maturing. I hope it will become common sense to have automated infrastructure tests. In the meantime, it’s the responsibility of those who do know to put the point across.
One concern is tooling. There are some great tools out there. AWS Spec and ServerSpec are two tools I would particularly highlight. That said, for many tools and languages, the tooling is still immature. Best practice for different use cases have not been established. You may find yourself hacking implementations, or using tools which are not widely adopted.
There are two large, intractable problems with infrastructure testing:
It’s expensive. If you want cloud infrastructure testing, you’ll need to pay for whatever you spin up. In particular, AWS charges by the hour for any instances. This can get expensive for tests that only take a couple of minutes.
It’s slow. It can be slow to do infrastructure related tasks. Provisioning, bootstrapping and configuring a single instance can take a few minutes. Likely longer. Backing up storage could take 10-20 minutes. That’s per scenario – so expect long test execution times, and slow progress on test creation.
There are other issues. Immutable infrastructure is an interesting case. By design, you’ve made it impossible to access your infrastructure. The only option is black box functional testing.
Not all infrastructure testing is worth it! Here’s an example Ansible playbook for configuring an etcd instance:
There’s a level of complexity in this code. But it’s mitigated by the declarative style of Ansible playbooks. Testing is used to mitigate complexity. I would argue that this code has little complexity to mitigate. It gets even worse with Terraform. Here’s an example which provisions some AWS EC2 instances:
Three compute instances, using the same AMI, and an instance size. That’s all we need! If we were to write unit tests, then they would be equal in length and complexity to the code they test. We should trust Terraform, since these tools have already been unit tested. We can get a better return on investment by testing riskier or more complex parts of our application.
One example of this would be an integration test. AWS Spec is a step in the right direction – we can directly test against AWS’s API to make sure our environments are up and running. Here’s an example:
This won’t just test Terraform’s ability to spin up instances. It makes sure that it succeeded, that your credentials work, and it doesn’t clash with other configurations.
There are problems in the way, but they are not insurmountable. We need to start investing time and effort into solving these issues.
As far as I can see it, there are three main things we can do right now:
I’ve recently been doing conference and meetup talks on infrastructure testing. It seems to be catching people’s attention – many have not considered it at all. Others are trying to solve the problem on their own, unaware of the tooling out there. It is up to us as a community to start talking more about it. If we start talking about it more, then we can start fixing the problems together.
As said before, many people are trying to solve this problem on their own. This is because we don’t know best practice yet. In contrast, web testing is a solved problem with best practice and mature processes. Examples include the page object pattern, or the test pyramid. As we share our experiences, we can start to develop these for infrastructure testing too.
Our processes are immature, but so is our tooling. I love Serverspec – it’s a great DSL. But it doesn’t do everything. On a recent project, we had functional infrastructure requirements. Serverspec wasn’t enough. We used Cucumber and plain Ruby for the infrastructure testing framework. I’m not convinced this is the best we can do. There’s nothing on the level of Selenium, or Capybara, or Gatling. And it gets worse. If you’re using Mesos or Kubernetes, what testing tools do you use?
Your infrastructure code is just as important as your application code. It also makes sense to apply the same best practices to infrastructure code. If you’re not currently testing your infrastructure as part of your pipeline, it would be wise to start thinking about why you’re not, and what you can do about it from now.
We face various problems – slowness, immaturity of tools, cultural barriers. But there’s no reason we can’t start tackling these right now. If we start raising the issue more, we can start developing good practices as a community. We can built upon the existing tool set. We can make infrastructure testing as common a practice as software testing.
If you want to read further about the topic, I also have a QCon talk on the subject where I discuss an infrastructure testing framework we built. My colleague Daniel has written a summary here, and my slides have been uploaded here.
This blog is written exclusively by the OpenCredo team. We do not accept external contributions.
SHARE






GOTOpia 2021 – Platform Engineering as a (Community) Service
Watch Nicki Watt’s talk on Platform Engineering as a (Community) Service at GOTOpia to learn what it takes to build a platform that is fit…
