
 Like all technologies, Cassandra operates according to certain principles and conventions. These conventions enable Cassandra to yield outstanding performance and support complex data needs, but this comes at the expense of some fundamental limitations. You should assess and understand these limitations before committing to Cassandra as a technology, and align your rollout of Cassandra with this understanding to ensure that future performance and ongoing operations are within your expected bounds.
Like all technologies, Cassandra operates according to certain principles and conventions. These conventions enable Cassandra to yield outstanding performance and support complex data needs, but this comes at the expense of some fundamental limitations. You should assess and understand these limitations before committing to Cassandra as a technology, and align your rollout of Cassandra with this understanding to ensure that future performance and ongoing operations are within your expected bounds.
We will cover each of the more complex topics in more detailed blog posts in the series. If you wish to receive notifications as they are published, please register for our newsletter via the form below.
Webcast: “Cassandra – The Good, The Bad and the Ugly”
We’ll also be hosting a webcast on Tuesday October 6th where you can hear first hand from our experts about these topics and ask questions of them. To secure your free place please register here.
The promise of Cassandr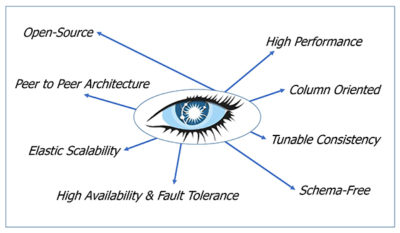 a
a
Cassandra has a number of strengths:
- Cassandra Performance
Cassandra supports very high throughput. In particular the Cassandra write path allows for high performance, robust writes.
- Elasticity
Cassandra is horizontally scalable. Read/write performance and capacity scales linearly as new hardware is added. Adding new hardware requires no downtime or disruption to consumers.
- Fault Tolerance
Cassandra has no single point of failure. Every node in the cluster is identical and can run on commodity hardware. There is no master server.
- Resilience
Data is automatically replicated to multiple nodes – which may be cross-rack (or cloud availability zone) and cross-datacenter. This can be used to ensure high availability across geographical regions.
- Flexibility
Cassandra uses columns to store data within rows, as rows can be of different length, i.e. have different numbers of columns per row, this leads to rows only as wide as the data in them and users have the ability to change the schema at runtime. With tunable consistency on a per read write operation, replication and read write consistency guarantees can be tuned either for speed or reliability for each query.
- Familiar SQL-like query language
CQL the Cassandra Query Language is syntactically similar to SQL, simplifying the onboarding of SQL developers.
Cassandra Performance Limitations to keep in mind
Writing data

Cassandra supports very fast write throughput subject to the following:
- Traditional transactions are not supported
Cassandra does not support rollback or locking mechanisms. Lightweight transactions are supported but are expensive.
- Mutation and deletes create overhead
Cassandra stores data in multiple immutable data structures (SSTables). Data is aggregated during read from these multiple tables. Updating data in Cassandra spreads data across multiple SSTables and deleting data creates tombstones which ensure that data is deleted correctly across the distributed cluster. These increase overhead for reads and generate increased pressure to clean up (compact) SSTables.
Querying data
Querying data in Cassandra is subject to certain limitations:
- Joins are not supported
It is not possible to join data from different tables into a single query – and there are no foreign keys. This can be worked around by de-normalising data, duplicating into query-oriented storage format or utilising an add-on reporting technology such as Apache Spark.
- Indexes supported with caution
Cassandra behaves as a large distributed Hashmap, and as such searches via the primary key which uniquely identify a row are very fast, however Secondary Indexes have limited use-cases and can significantly impact performance if applied incorrectly. It is vital that appropriate key and clustering columns are modelled for your querying needs.
- Eventual Consistency
Data is automatically replicated across the cluster. Even with this process, there is a latency and with a masterless configuration, we are subject to eventual consistency. This can be mitigated by using QUORUM reads and writes if required and the incurred overhead is acceptable.
Data modelling
Data modelling in Cassandra is a complex topic. Here we will provide four basic rules:
- Distribute data evenly
Partition keys should be chosen so that data is evenly distributed around the Cassandra ring to ensure that no one node is processing excessive traffic.
- Avoid aggregating data from multiple partitions/nodes
Reads which require multiple nodes to respond will take longer to process and aggregate data, with minimum response time equal to that of the slowest-responding node. Querying across partitions may incur this overhead depending on partition strategy and location
- Structure by queries
Writes are cheap in Cassandra, so there is minimal overhead for duplicating data. Remember that there are no foreign keys, so denormalising into larger tables with duplicated data can significantly simplify reads. Aim to write data in such a way that your queries can be fulfilled by reading from a single partition.
- Avoid updates and deletes
Updates and deletes significantly complicate de-normalised and duplicate data models. In addition, there is a heavy operational overhead in clearing mutations and deletes from the ring. Cassandra performs best with append-only, immutable data.
Operations
The default settings for Cassandra can yield a high performance cluster. However, once operating in a non-trivial production environment operational oversight is inevitable. The distributed nature of Cassandra and unfamiliarity of its data model can create an operational skills gap.
A Cassandra DBA needs to understand:
- Distributed systems and consensus
- Java Virtual Machine tuning
- Various Cassandra production support processes such as compaction
- Monitoring and alerting requirements
Certain operations will also require manual intervention from ops:
- Node Failure. Where a node goes down it must be addressed manually.
- Failed operations. In some cases, updates and writes may fail to synchronise across the cluster correctly. Regular repairs are required.
These gaps can certainly be filled with online training and will definitely benefit from at least one operationally experienced individual within your organisation “taking on” Cassandra.
When should I use Cassandra?
Having considered the promise and limitations of Cassandra, we finish with a recommendation for the areas in which Cassandra excels.
- Cassandra is ideally suited to relatively immutable data where updates and deletions are the exception rather than the rule.
- This includes handling high-throughput firehoses of immutable events such as personalisation, fraud detection, time series and IOT/sensors.
- If your application does not exactly fit this mould it may still benefit from Event Sourcing – storing all changes to the system as an immutable event log rather than mutable state
- Frameworks such as CQRS provide structure for reasoning about events.
- Technologies such as Spark provide the means to generate aggregate (cross-table) datasets from Cassandra data and generate reports.
Who else uses Cassandra?
- E-commerce platforms including Ebay and Wiggle use Cassandra for their recommendation engines.
- Digital entertainment giants such as Sky, Netflix, Spotify and SoundCloud use Cassandra to provide their online services
- NASA use Cassandra to store vast amounts of security data
- GitHub and Instagram use Cassandra for analytics
- Barracuda and Iovation use Cassandra for fraud detection
This is the first post in our blog series “Cassandra – What You May Learn The Hard Way.” Get the full overview here.
Register here to attend our free webinar “Cassandra – The Good, the Bad, and the Ugly” on October 6th!
Sign up to receive updates via email
This blog is written exclusively by the OpenCredo team. We do not accept external contributions.







