Read Matt Farrow’s blog as he explores the potential for using Open Policy Agent to filter and mask data being sent to and read from Apache Kafka.

This blogpost is about the Opa Single Message Transformer component, the code for which is available here.
Apache Kafka is the central data distribution mechanism in many organisations. Very often, some of the data in Kafka will be sensitive and therefore it is critical to manage what data flows into and out of it, as well as to where.
At a high level, we want the ability to restrict the data that is sent both into and from Kafka by processing the records as they are transferred. We should be able to filter the records so that only a subset is transferred, or mask some of the fields so that they are not transferred and a dummy mask value is sent in its place. Finally, it’s important to be able to apply this filtering and masking regardless of where the data is being received from or sent to.
At OpenCredo we always look to build systems using reliable, repeatable methods, such as Infrastructure-as-code (Iac). When it comes to policies, this is no exception. We have been using a tool called Open Policy Agent (OPA) recently in several projects and decided to build a proof of concept integrating it with Kafka feeds to gain insights into how we could use them together to solve real world problems.
Open Policy Agent is a tool that allows the use of a high-level declarative language called Rego to specify policies as code, such as which data can flow from where to where.
Here’s an example of an OPA policy that checks that a server doesn’t offer the HTTP protocol and doesn’t expose port 80 publicly:
allow := true {
count(violation) == 0
}
violation[server.id] {
some server in public_servers
"http" in server.protocols
}
violation[server.id] {
some server in input.servers
80 in server.open_ports
}Checking for violations like this is a very natural use case for OPA but it can be used much more broadly than just validating configuration files. Software needs to be written to evaluate rules against whatever the policy describes, and that’s what we aim to do here. The policy is decoupled from the implementation of the software, is relatively readable to less technical people, can evolve without any changes to the code and can be made available to interested parties to scrutinise.
I had never used Kafka Connect, let alone written any code for it, and I was not sure that it was possible to use OPA from Java. These were the two areas of uncertainty that I wanted to get an understanding of before I tried to build anything.
First, I read around the different options for adding these filtering and masking capabilities when reading and writing to Kafka. Kafka Connect connects a vast range of third party systems and formats to Kafka via its vast ecosystem of data sources and data sinks. Kafka Single Message Transforms are components that can be configured to run with both sinks and sources, meaning that we can write a component once and use it to filter both data being written to and read from Kafka using the full range of sinks and sources. So this seemed like a good fit.
Here’s the data flow when loading data into Kafka:
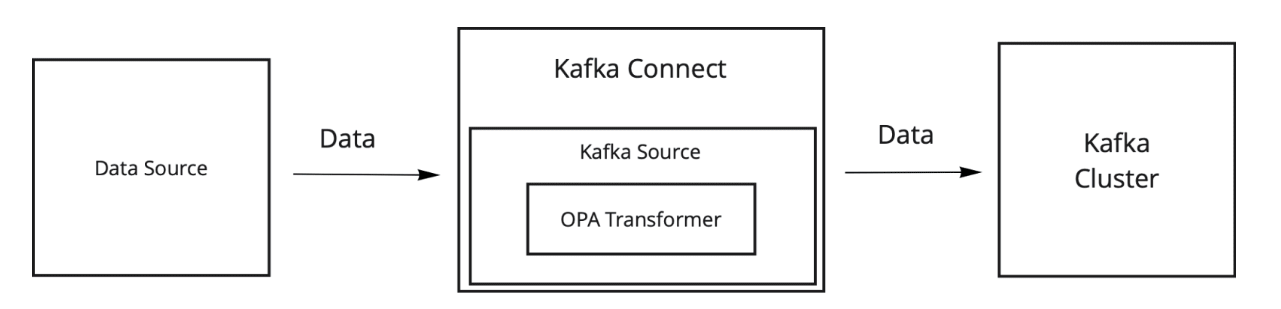
And when consuming data from Kafka:
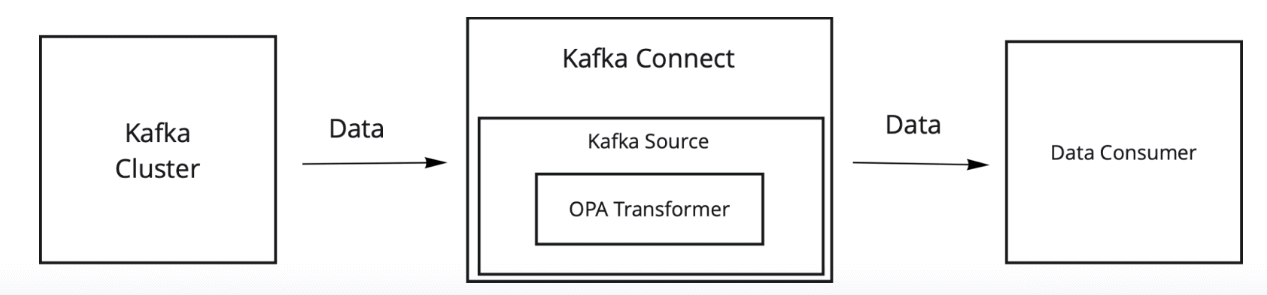
OPA policies are usually distributed in “bundles” – basically rego files and data for policies to use, wrapped together in a compressed file. Kafka is Java-based and there is currently no straightforward way to work with standard OPA bundles from Java. However, OPA allows you to compile a bundle (have we defined a bundle yet?) to WebAssembly, so this presented an integration possibility.
WebAssembly is a binary instruction format that many languages can be compiled to, and there are libraries that enable you to run WebAssembly from Java code. I looked at several of these and it was clear that doing this would require significant investment of time to get it to work. After spending some time doing that with little to show for it, further searching led me to find the catchily titled OPA WebAssembly SDK for Java – developed by Sangkeon Lee. This seemed to offer exactly what I needed – the ability to run OPA in-process and query it.
You can find that library here:
I wanted to consider whether this library was one that I wanted to rely on. It is arguably not ideal that it is in an early stage of development and is maintained by a single person, but he has written a guide to OPA which includes a chapter that goes into great detail around how he wrote the library! (https://sangkeon.github.io/opaguide/) That would be helpful if we decided we wanted to maintain this functionality ourselves, perhaps by forking the library. This library was so new that I had to email the author to ask him to put it on Maven Central.
The example code on the website worked quite easily and I soon had Java code querying OPA policies.
Documentation on Single Message Transformers is limited but there are lots of blog posts talking about them (and here we are, doing the same).
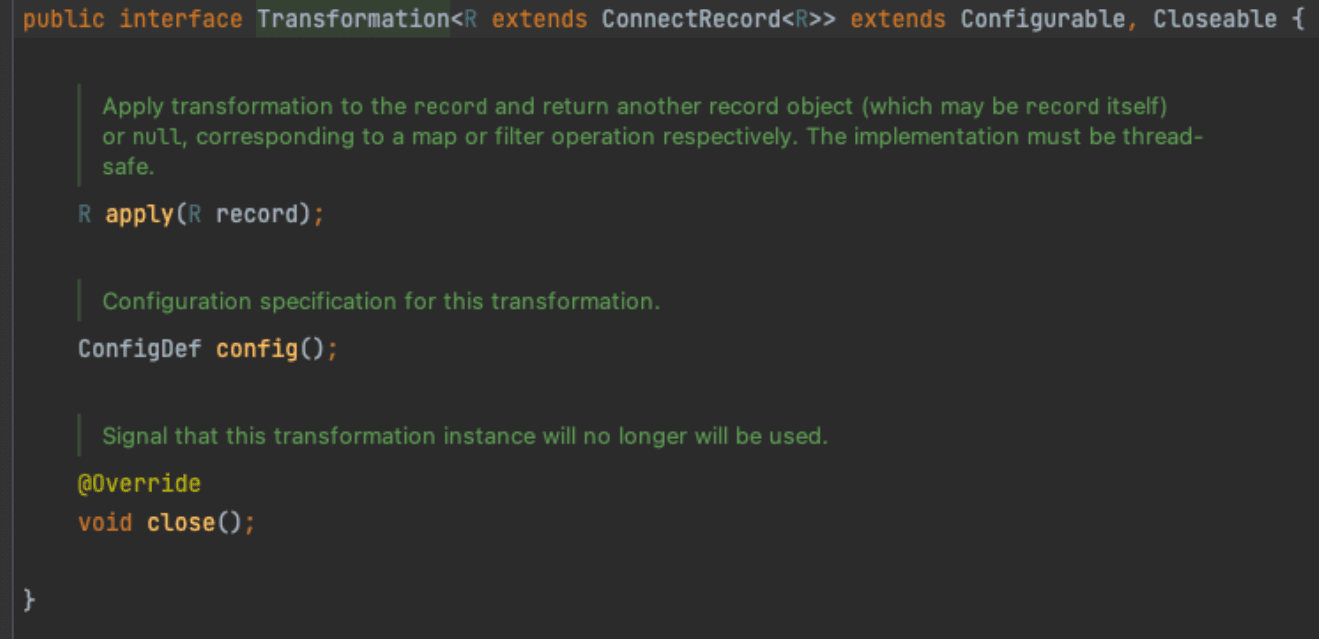
A transformer has a configure() method where it checks that it has suitable values for all the configuration options that it declares.
It also has an apply() method that takes a record and allows you to transform it however you see fit within the restrictions implied by the schema, or return null
I wanted to get a basic transformer working against a local Kafka instance. A transformer makes no sense in isolation. I configured an FsSourceConnector to test it with. Getting this working took much longer than I expected because it is not supplied with Kafka and the documentation was again very lacking. I had to configure it with policy class for example. I only found what a suitable configuration value might be by looking at the Kafka Connect codebase for packages that might be relevant and then a lot of trial and error.
These issues were resolved after a while and I wrote a very simple transformer that filtered out all records by returning null. Writing this code was very simple compared to setting up the test environment.
Having Java calling OPA successfully and a basic transformer working, I was then happy to start building the transformer for real.
At this point, the shape of what I was going to build was fairly clear. I wanted the transformer to call OPA entrypoints to determine:
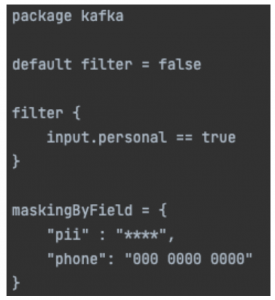
Here’s an example configuration specifying that records with the “personal” field should be filtered out and that the “pii” and “phone” fields should be masked. For each field you mask, you can choose which string to mask it with, which can be helpful if you want your data to still be in the format that downstream systems expect.
To query OPA about whether to filter a record would require one call to OPA per record because we want it to be able to make a decision based on the fields on the record. It should only be necessary to query whether to mask a field and what to mask it with once – this information can be cached after it’s retrieved the first time.
When the component sends a request to OPA asking whether to filter out a record, it has to serialise it into JSON as this is the request format that OPA requires. This is inherently much slower than if you were using OPA from Go, in which case you could just pass a Go struct that OPA understands natively – zero marshalling required.
We want the system to be able to handle changes to the policy bundle. The library we are using doesn’t handle this, so we need to. When the bundle is hosted on the file system, you can listen for file updates, though I found there was up to a ten second delay in seeing these updates so the tests can run frustratingly slowly. When the bundle is hosted on a web server, it polls for changes at a configurable time interval.
In order to test this component, we need to run it against policies compiled to WebAssembly bundles. Ideally we would do this compilation as part of the test classes’ run, however the OPA command line tool is required to perform this process, to my knowledge, so we would need a reliable way of running this as part of the tests, and on multiple platforms. This is not straightforward.
So for now, I have checked the WebAssembly bundle files into the repository alongside the rego files that they were generated from. This is really unsatisfactory because the tests are made less readable by the fact that the regos files are outside of the test classes. There is also no way to tell whether the checked in bundle files contain the same logic as the checked in rego files.
The repository hosting this component has detailed instructions on how to get this component up and running yourself to filter and mask data on a local Kafka installation.
In my opinion, the proof of concept was a real success. The component fits cleanly into the Kafka Connect framework and the use of OPA to configure it is flexible and feels natural. Some of the minor frustrations I’ve mentioned could potentially be addressed though.
There is no reason that standard OPA bundles can’t be evaluated directly from Java. In fact the Rego Java Interpreter project does just this, and would enable standard OPA bundles to be packaged up inline in the Java unit tests.
Executing directly rather than via WebAssembly may also be more performant. I have not performance tested or tuned the component. When we have some real performance requirements, we can do that and judge whether the functionality delivered here is worth the performance difference.
Writing a blog post about this component has required me to explain what I did and, to some extent, to justify design choices I made. This was a useful exercise because it was illuminating when I struggled to do that, highlighting several areas that I chose to improve.
This blog is written exclusively by the OpenCredo team. We do not accept external contributions.
SHARE





Platform Engineering Day Europe 2024 – Maturing Your Platform Engineering Initiative (Recording)
Watch the recording of our CEO/CTO, Nicki Watt from the KubeCon + CloudNativeCon 2024 on her talk “To K8S and Beyond – Maturing Your Platform…
GOTO Copenhagen 2023 – The 12 Factor App For Data (Recording)
Watch the recording of our Technical Delivery Director, James Bowkett from the GOTO Copenhagen 2023 conference for his talk ‘The 12 Factor App For Data’
The 2023 Mayor’s Business Climate Challenge (BCC) – Final Part
Learn more about our efforts and our progress towards becoming an environmentally friendly company for the Mayor’s Business Climate Challenge (BCC) in 2023 in this…