June 23, 2015 | Cloud, DevOps, Terraform Provider
Working with OpenCredo clients, I’ve noticed that even if you are one of the few organisations that can boast ‘Infrastructure as Code’, perhaps it’s only true of your VMs, and likely you have ‘bootstrap problems’. What I mean by this, is that you require some cloud-infrastructure to already be in place before your VM automation can go to work.
WRITTEN BY

Re-blogged from http://blog.jmips.co.uk/
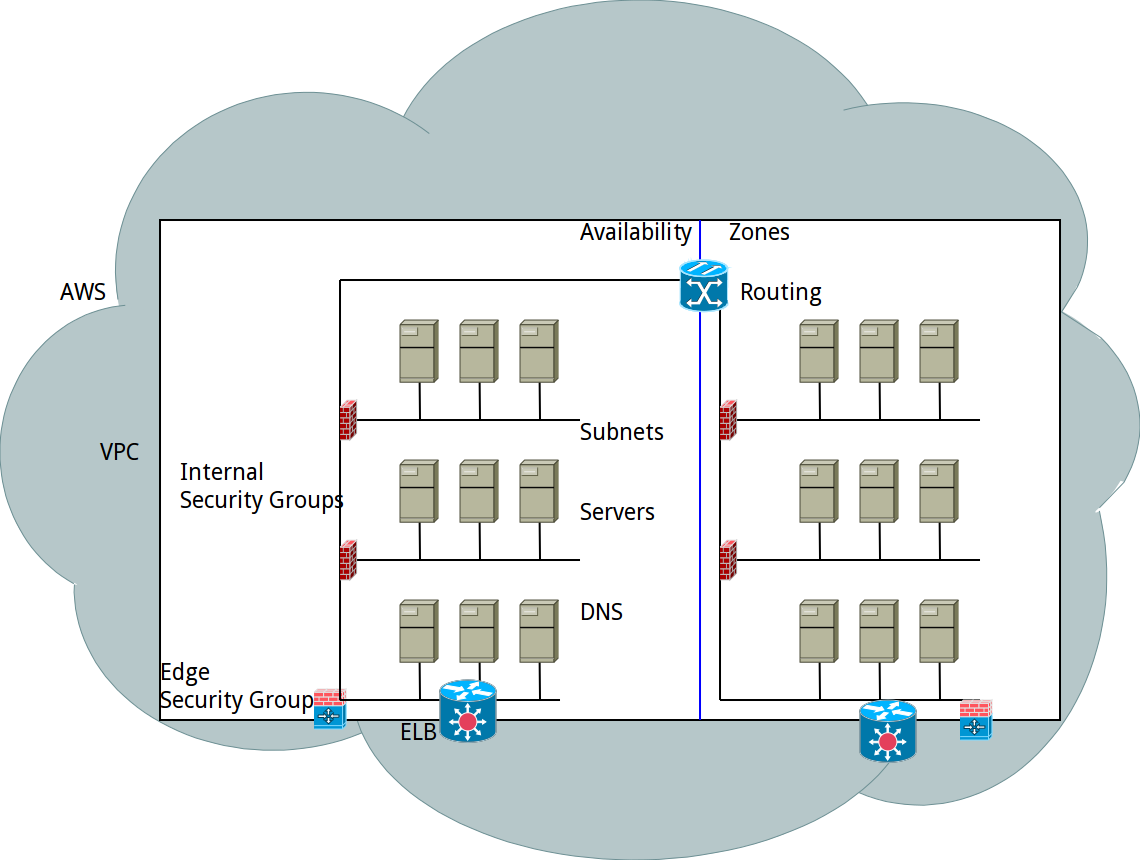
I’ve seen a lot of AWS (Openstack, Google Compute too ) environments where objects like VPCs, subnets, routing etc. is all put in by hand – or maybe with some static scripts. A little beachhead manually deployed inside your cloud-provider, all before the VMs are spun up and provisioned automagically by your tools.
Wouldn’t it be better if your Cloud networking and associated configuration was deployed at the same time, and dynamically linked to the VMs being provisioned?
Even better – what if scaling out everything across A-Zs, or changing machine types across your estate was just a configuration parameter? How about a second copy of everything for DR or staging?
It’s been possible to do this for a while. A few options include.
Terraform is the tool I’ve been waiting for for years. It’s only been going a year or so, but has come along leaps and bounds in the last 6 months, and as ever, Hashicorp are very responsive on Github to feature requests, bugs and pull requests.
It has the ability to do complete cloud-infrastructure creation, and through it’s DSL link the various components together programatically.
This definition of useful parts of cloud-infrastructure can be defined as a module, with parameterised inputs – and used again and again in different deployments, in combination with other modules.
Why is this powerful? A full worked example of Terraform using these capabilities would be a set of blog posts by themselves, but using AWS as an example, let’s look at an overview of what you could do:
Management module – Define a VPC, subnet, NAT box, appropriate routing, security groups, and a Puppetmaster.
Front-end web-server module – Define a tier of 5 front-end webservers in their own subnet – link them dynamically to a public ELB.
Middleware web-server module – Define a tier of 5 messaging brokers and 5 custom middleware servers – link them to an ELB
DB layer module – Define a tier of 5 MongoDB servers
All modules – Automatically create DNS records for all infrastructure. Consume security groups from the Management module. Parameterise the module input to create this across A-Zs on demand, including sizing and server numbers.
The Terraform code that calls these modules can pass details between them, so for instance an ELB in one module can be made aware of an instance ID created in another module.
Now we have modules that can be sized, re-used and linked-together as appropriate, we can define environments using them. The same provisioning code can be used in Test, Staging and Production – with suitable input parameters.
While Terraform can directly call hooks for provisioning tools, ( eg. Puppet or Chef. ) usually the VMs it creates are in private networks, not accessible from the internet, or the machine running Terraform.
The problem becomes, how to pass data to VMs for use in initial bootstrapping, where you can’t contact the VMs themselves?
Cloud-Init uses Instance Metadata ( a free-form text field associated with a VM), retrieved over a private internal cloud API, to do first-boot configuration. Most cloud providers have this metadata concept, including Openstack and Google Compute.
Examples of templated information passed from Terraform to Cloud-Init via instance metadata:
eg.
It’s important to note that Cloud-Init is not a configuration management tool – here it’s merely a thin shim between Terraform and proper configuration management.
Why Puppet?
It’s true there are a few other tools we could substitute here, but the important thing is to have a ‘pull’ based deployment model.
Why is this necessary?
As mentioned before, we cannot directly contact the VMs being spun up in private networks, a pull-based model allows the VMs themselves to pull their configuration when they’re ready.
We could do master-less puppet, with each VM doing a Github checkout of puppet-code, and locally applying it, but this relies on external code repositories, and puts a full copy of secrets on each VM, both are security risks.
Cloud deployments made using this stack of tools are truly self contained, fire-and-forget.
The only connectivity requirement the provisioning user/service needs is to the Cloud Provider API.
Run Terraform, wait for it to complete in a few minutes – then the asynchronous provisioning takes over as the VMs boot to bring your infrastructure into service.
This blog is written exclusively by the OpenCredo team. We do not accept external contributions.
SHARE






Cloud for Business in 2023: Raconteur and techUK webinar (Recording)
Check out the recording of our CEO/CTO Nicki Watt, and other panellists at the Raconteur and techUK webinar discussing “The Cloud for Business Report,” which…
Lunch & Learn: Secure Pipelines Enforcing policies using OPA
Watch our Lunch & Learn by Hieu Doan and Alberto Faedda as they share how engineers and security teams can secure their software development processes…